フィッティング1(測定データの準備)¶
たとえば実験で得られたバラツキのある測定データを既知の関数で近似したい. 関数の形は理論的な要請などによりあらかじめ決まっているとし,その係数,定数を調整してなるべく測定データに沿うようにしたいとする. 最小二乗法(Least squares method)による関数のフィッティングを行ってみよう.
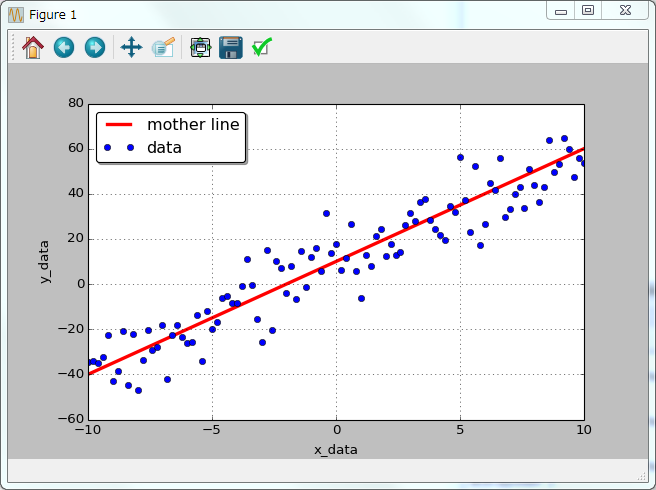
まずは準備として,乱数を使って実験データを摸擬したバラツキのあるのデータのリストを作ろう. \(f(x) = 5x + 10\) という1次関数を定義する(この5と10がフィッティングにより得たい数値である).この関数による直線データに乱数によるバラツキを加えて測定データとする.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import numpy as np
def f(x):
return 5.*x + 10.
xdata = np.linspace(-10, 10, num=101)
np.random.seed(1234)
ydata = f(xdata) + 5.*np.random.randn(xdata.size)
print(ydata.size)
plt.figure(figsize=(8,5))
plt.plot(xdata,f(xdata),'r-', label='mother line', linewidth=3)
plt.plot(xdata,ydata,'bo', label='data')
plt.xlabel('x_data')
plt.ylabel('y_data')
plt.legend(loc='best',fancybox=True, shadow=True)
plt.grid(True)
plt.show()
|
3,4行目:f(x)を,5.*x+10.を計算して,その計算結果を返す(return)関数であると定義(define)している. 例えば,x=1.の場合f(1.)=5*1.+10.=15.と値を返す.
6行目:データを生成するにあたって,まずは横軸(測定点,測定時間..)となるデータリストを作る.numpyのlinspaceは指定の範囲(-10~10)に指定の 個数 (num=101個)の等間隔のリストを生成する. ここでは,[-10. -9.8 -9.6 ... -0.2 0. 0.2 0.4 ... 9.6 9.8 10. ]が生成される.
Note
6行目np.linspace(-10, 10, num=101)の代わりに,np.arange(-10,10,0.2)としても上記と同じデータリストを作ることができる.こちらの命令,-10からはじめて0.1ずつ増やしながら10までのデータを生成する,である. 増分 を指定している.
7,8行目:乱数を生成する.8行目のrandom.randnは標準正規分布(平均=0,分散(\(\sigma^2\))=1のガウス分布)に従う数を生成する. ただしここで生成される乱数は疑似乱数と言って,7行目のseedで指定される種数(いくつでもよい)によって決まったリストを生成する.7行目はなくてもよい.なければ,実行のたびに異なる乱数リストを生成する.
Note
その他にもさまざま分布に従った乱数生成が用意されている.たとえばnormalを使えば,平均・分散が指定できる.normal(10.,5.,100)とすれば平均10,分散5の乱数を100個生成する. その他の方法については ⇒Link
8行目:f(xdata)は,3行目で定義した関数f(x)に生成したxdataを入れるという意味である.さらに,生成した乱数を(適当に)5倍した上でf(x)に加えている. 乱数を加えることで,バラツキのある測定データを疑似的に生成できたことにしている.
9行目:一応生成した測定データの個数を確認.xdataと同じ101個のはずである.
11行目以降:生成したデータをプロットする. 12行目:横軸にxdata,縦軸にf(xdata)をプロットする.つまり,関数f(x)そのものである.このようにplot命令の中で関数を呼び出して計算することもできる. 13行目:8行目までで用意していたxdataとydataをそれぞれ横軸,縦軸としている.こちらはバラツキのある測定データのつもりで,青丸でプロットしている.

Note
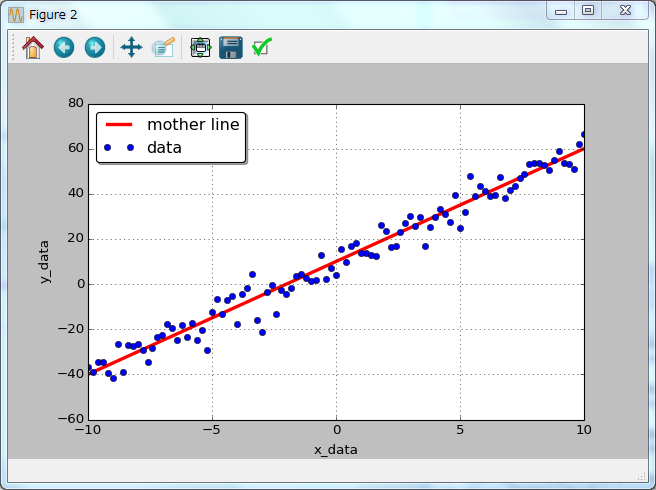
乱数といってもrandnが生成するのは,疑似乱数である.種数(random.seed(1234))が同じであれば,常に同じ値のリストになる.種数を変えれば全く異なるリストになる.以下はseed(1235)とした場合である.
Note
8行目をnormalを使って書き換え,分散を指定する.たとえば,「ydata = f(xdata) + 5.*np.random.normal(0.,2.,xdata.size)」にすると