�P�D���e
�O��Ɠ��l�A3��ڂ�CTD�����l���g���āA�ȒP�ȓ��v�������s���B
�ڕW�����ϒl�A���U�A�W����(�V�O�})�̎Z�o�A����ѕ��ϒl�}�V�O�}�ȓ��̃f�[�^
�̒��o�B
�Q�D�O�m��
�W�����̓f�[�^�̂����\���w�W�ł���A�Ⴆ�f�[�^�̕i���Ǘ��ɗp����B

�}�P�F500�`1000m���[�̉����f�[�^�݂̂𒊏o���A�p�x���z��`�������́B�_���̓f�[�^�̊m�����x���z�B������x�͐��K���z���Ă���B�V�O�}�i�Ёj�Ƃ͕W�����̂��ƁB
|
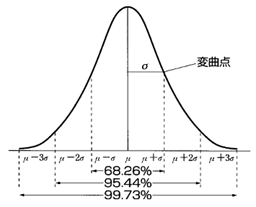
�Q�ƁFhttp://homepage1.nifty.com/QCC/sqc2/gauss3.gif
�R�D���ϒl�i�O�łɎ��s�ρj
�O��g�����uDO���[�v�v���g�p����B���ϒl�͌����܂ł��Ȃ��A
�u���v�i���a�j/�f�[�^���v
�Ōv�Z�����B
�S�D���U�E�W����
�W�����͕��U�̕������Ȃ̂ŁA���U�̌v�Z���킩���Ă���悢�B���U�́u���ς���ǂꂾ������Ă��邩�v�Ƃ����f�[�^�̎U����̎w�W�ł���B�܂��c�������a�����߁A����ɕ��U���v�Z����B�c�������a�Ƃ͂��̖��̒ʂ�A�i�f�[�^�|���ϒl�j��2��̑��a�ł���B���U�����߂���͂��̕����������߂邾���ŁA�W���������܂�B
�@�@�@![]() ---(1)
---(1)
�@�@�@![]() ---(2)
---(2)
�@�@�@![]() ---(3)
---(3)
�܂���(1)����DO���[�v�Ő��䂵�Ă��悢�B(2)���́u�f�[�^�̌��v�ł��邪�A�f�[�^�̑����ł���un�v��������ꍇ�Ɓun-1�v��������ꍇ�ł͈Ӗ����قȂ�B�O�҂ł͓���ꂽ���U���u�W�{���U�v�A��҂ł͓���ꂽ���U���u�s�Ε��U�܂��͕ꕪ�U�v�Ƃ����B�s�Ε��U�ɂ��(3)�����瓾������̂́A�W���덷�ƌĂ��B�ڂ����͓��v�̋��ȏ��ɏ���B�ȏ�̂��Ƃɓ���Ă����A�ȉ���2�_���s���B
�@
�����l���畽�ϒl�E�W�����i�V�O�}�A�������̓Ёj�����߂�B
�A �ُ�l���u���ρ}2�Ђ���O��Ă�����́v�ƒ�`���āA�ُ�l����ʂɏo���Ă݂悤�B
(�q���g)
�P�j�c�������a�̌v�Z
���ϒl�͂��łɌv�Z����A�ϐ�heikin�ɑ������Ă���Ƃ���B
real(8) goukei,heikin,hensa
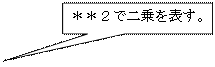 real(8) bunsan
real(8) bunsan
do k=1, 345
�@bunsan=bunsan+(csal(k) – heikin)**2
enddo