この回でやること
スペクトル解析とは、時系列に含まれる変動を「周期ごとの強さ」として見る方法である。SOI のような大気海洋変動の時系列には、季節スケール、数年スケール、十年スケールに近い変動が混ざっている。
ここでは同じ SOI 時系列に対して、3つの代表的な方法を適用する。
| 方法 | 見るもの | 特徴 |
|---|---|---|
| Blackman–Tukey 法 | 自己共分散から作るスペクトル | なめらかで安定。ただしピークは丸くなる。 |
| FFT 法 | フーリエ変換から直接作るスペクトル | 基本的で分かりやすい。分割平均すれば信頼区間も考えやすい。 |
| MEM | ARモデルから推定するスペクトル | ピークが鋭く出る。ただしモデル次数に依存する。 |
BT法の説明
1.1 まず「ラグ」を考える
Blackman–Tukey 法(BT法)は、元の時系列をいきなりフーリエ変換するのではなく、まず自己共分散を計算する方法である。
自己共分散を理解するためには、まず ラグ(lag) を考える。ラグとは、時系列を何か月ずらして比べるか、という「ずらし幅」である。
| ラグ | 意味 | SOI 月平均データの場合 |
|---|---|---|
| lag = 0 | ずらさずに自分自身と比べる | 元の分散に対応する |
| lag = 1 | 1か月ずらして比べる | 今月の SOI と翌月の SOI の似ている度合い |
| lag = 12 | 12か月ずらして比べる | 1年前または1年後と似ている度合い |
| lag = 48 | 48か月ずらして比べる | 約4年周期の変動があれば似た構造が出やすい |
つまり、自己共分散とは「少しずつずらした時系列どうしが、どれくらい似ているか」を数値化したものである。
1.2 なぜ自己共分散からスペクトルが出るのか
もし時系列の中に周期性があれば、あるラグで再び似た形が現れる。たとえば 48か月程度の周期が強ければ、lag = 48 付近でも自己共分散が大きくなりやすい。
したがって、自己共分散の中にも周期的な構造が含まれる。その自己共分散を周波数領域に変換したものが、Blackman–Tukey 法のスペクトルである。
この式は難しく見えるが、考え方は単純である。ラグごとに求めた自己共分散 γ(k) を、余弦関数 cos(2πfkΔt) を使って周期ごとの強さに変換している。
1.3 m とは何か
ここで重要になるのが m である。m は、自己共分散を何か月先のラグまで使うかを決める値である。これを最大ラグという。
たとえば、月平均 SOI データで m = 50 とした場合、lag = 0 から lag = 50 か月までの自己共分散を使ってスペクトルを作る、という意味である。
| m の値 | 使う自己共分散 | スペクトルの特徴 |
|---|---|---|
| 小さい m | 短いラグまでしか使わない | なめらかで安定するが、周期の細かい違いは見えにくい |
| 大きい m | 長いラグまで使う | 分解能は上がるが、推定が不安定になりやすい |
なぜ大きいラグが不安定かというと、ずらし幅が大きくなるほど、重なって比較できるデータ数が減るからである。たとえば全体が 564 か月のデータでも、lag = 100 では比較に使える組み合わせは 464 個に減る。
1.4 Blackman 窓をかける理由
BT法では、最大ラグまでの自己共分散をそのまま使うのではなく、ラグ方向に窓関数をかける。今回使っているのが Blackman 窓である。
大きいラグの自己共分散は不安定になりやすいので、その影響を少しずつ弱める。これにより、スペクトルのギザギザや不自然な振動を抑えることができる。
w(k) は、lag が小さいところでは大きく、最大ラグ m に近づくほど小さくなる。つまり、「信頼しやすい短いラグを強く使い、不安定な長いラグを弱く使う」ための重みである。
FFT法の説明
FFT法は、時系列をさまざまな周波数の波に分解する方法である。04で扱った離散フーリエ変換を高速に計算するアルゴリズムが FFT である。
この X(f) は複素数であり、その絶対値の2乗をとると、その周波数の波がどれくらい強いかを表すパワーになる。
今回の FFT スクリプトでは、時系列全体をそのまま1回だけ FFT するのではなく、時系列を nseg=10 個に分割し、それぞれのスペクトルを平均する。これにより、ギザギザしたスペクトルを少し安定させる。
また、ゼロパディングを行い、周波数軸を細かくしている。ただし、ゼロパディングは本質的な分解能を増やすものではなく、図を滑らかに見せるための補間に近い。
MEM法の説明
3.1 MEMは「時系列を予測するモデル」からスペクトルを作る
最大エントロピー法(Maximum Entropy Method; MEM)は、FFT や BT法とは考え方が少し異なる。FFT や BT法は、観測されたデータそのもの、あるいは自己共分散を周波数に変換する。一方、MEM はまず時系列を自己回帰モデル(ARモデル)で表し、そのモデルからスペクトルを推定する。
ARモデルの基本的な考え方は、現在の値は、過去の値の組み合わせからある程度予測できるというものである。
SOI のような時系列では、今月の値は完全にランダムに決まるわけではなく、前月や数か月前の状態とある程度関係している。MEM はこの「過去から現在を予測する構造」を使って、どの周期の変動が強いかを推定する。
3.2 AR係数とは何か
ARモデルは、次のように書ける。
ここで a₁, a₂, ..., aₘ が AR係数 である。AR係数とは、過去の値をどのくらいの重みで使って現在の値を説明するかを表す係数である。
| 記号 | 意味 |
|---|---|
| a₁ | 1か月前の値をどれくらい使うか |
| a₂ | 2か月前の値をどれくらい使うか |
| aₘ | mか月前の値をどれくらい使うか |
つまり、AR係数は「過去の記憶の重み」である。ある周期的な振動が時系列の中に含まれていれば、その振動を再現するような AR係数が推定される。
3.3 m は MEM では「モデル次数」
MEM にも m が出てくる。ただし BT法の m とは意味が少し違う。
| 手法 | m の意味 |
|---|---|
| BT法 | 自己共分散を何か月先のラグまで使うかを表す最大ラグ |
| MEM | 何か月前までの値を使って現在を予測するかを表すモデル次数 |
MEM で m = 67 とする場合、1か月前から67か月前までの値を使って、現在の値を説明する ARモデルを作る、という意味である。
3.4 予測誤差分散とは何か
ARモデルで現在の値を予測しても、完全には一致しない。予測しきれずに残った部分を 予測誤差 という。
この予測誤差の大きさを分散として表したものが 予測誤差分散 であり、式では σ² と書く。
予測誤差分散が小さいほど、ARモデルが時系列をよく説明できていることを意味する。逆に大きい場合は、過去の値だけでは説明できないランダムな成分が大きいということになる。
3.5 AR係数と予測誤差分散からスペクトルを作る
MEMスペクトルは、推定された AR係数と予測誤差分散を使って、次の式で求める。
分母の部分は、ARモデルが周波数 f の振動に対してどのように応答するかを表す。ある周期の振動を ARモデルが強く持っている場合、その周波数でスペクトルのピークが鋭く現れる。
MEMは短い時系列でも鋭いピークを出しやすい。一方で、モデル次数 m を大きくしすぎると、実際には存在しないピークを作ってしまうことがある。
スクリプトの説明と実行
ここからは、Jupyter Notebook 上で順番に実行することを想定したコードである。基本的には、下のブロックを順番にコピペして実行すればよい。
4.1 最初のセッティング(共通)
最初に必要なライブラリを読み込み、解析期間や入力ファイル名を設定する。ここでデータの読み込み、期間選択、月ごとの連続性チェック、平均除去まで行う。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import chi2
# -----------------------------
# 1. 共通設定
# -----------------------------
fname = "SOI_timeseries_updated.txt"
# 解析期間
start_year = 1951
end_year = 1997
# 前処理
remove_mean = True
remove_linear_trend = False
# 図の保存
save_figure = False
def load_soi_data(fname):
df = pd.read_csv(fname, sep=r"\s+", engine="python")
required_cols = ["YEAR", "MONTH", "SOI"]
for col in required_cols:
if col not in df.columns:
raise ValueError(f"Required column {col} not found. Columns = {list(df.columns)}")
df["DATE"] = pd.to_datetime(dict(year=df["YEAR"], month=df["MONTH"], day=1))
df = df.sort_values(["YEAR", "MONTH"]).reset_index(drop=True)
return df
def select_period(df, start_year=None, end_year=None):
out = df.copy()
if start_year is not None:
out = out[out["YEAR"] >= start_year]
if end_year is not None:
out = out[out["YEAR"] <= end_year]
return out.reset_index(drop=True)
def check_monthly_continuity(df):
ym = df["YEAR"] * 12 + df["MONTH"]
dym = ym.diff().dropna()
if np.all(dym == 1):
print("OK: monthly data are continuous.")
else:
print("WARNING: monthly sequence is not continuous.")
print("Unique month-step values:", np.unique(dym))
def detrend_linear(x):
n = len(x)
t = np.arange(n, dtype=float)
coef = np.polyfit(t, x, 1)
trend = np.polyval(coef, t)
return x - trend
def preprocess_series(x, remove_mean=True, remove_linear_trend=False):
x = np.asarray(x, dtype=float)
x = x[np.isfinite(x)]
if len(x) == 0:
raise ValueError("No valid data in time series.")
if remove_mean:
x = x - np.mean(x)
if remove_linear_trend:
x = detrend_linear(x)
return x
# -----------------------------
# 2. データ読み込みと前処理
# -----------------------------
df = load_soi_data(fname)
df_sel = select_period(df, start_year=start_year, end_year=end_year)
print("Selected period:", df_sel["YEAR"].min(), "-", df_sel["YEAR"].max())
print("Number of months:", len(df_sel))
check_monthly_continuity(df_sel)
x = preprocess_series(
df_sel["SOI"].to_numpy(),
remove_mean=remove_mean,
remove_linear_trend=remove_linear_trend
)
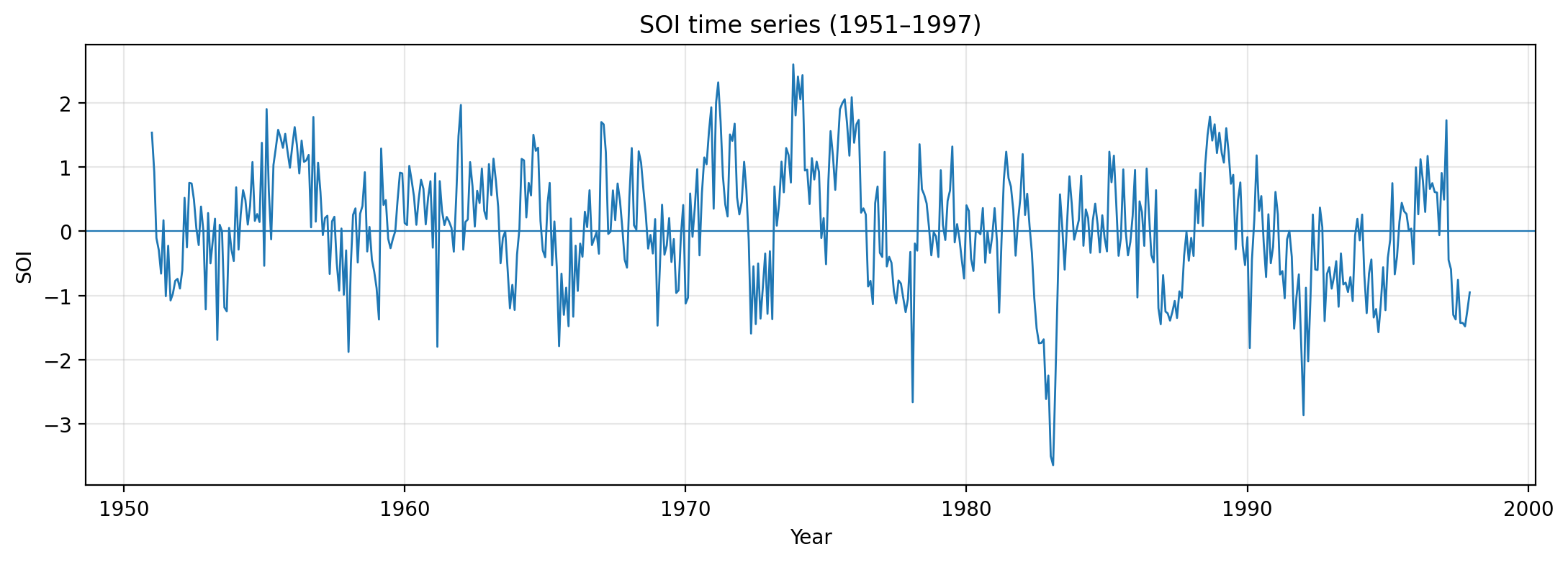
# 時間軸確認用の図
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(df_sel["DATE"], df_sel["SOI"], color="black", lw=1.0)
ax.axhline(0, color="gray", lw=0.8)
ax.set_title(f"SOI time series ({start_year}-{end_year})")
ax.set_xlabel("Year")
ax.set_ylabel("SOI")
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()このブロックのポイント
- pd.read_csv(..., sep=r"\s+") は、空白区切りのテキストファイルを読む指定である。
- pd.to_datetime(...) により、YEAR と MONTH から日付列を作る。
- select_period で 1951–1997 年だけを取り出す。
- check_monthly_continuity で、月が抜けていないか確認する。
- preprocess_series では、平均を引いて 0 を中心とする変動にしている。
4.2 BT法で計算&図
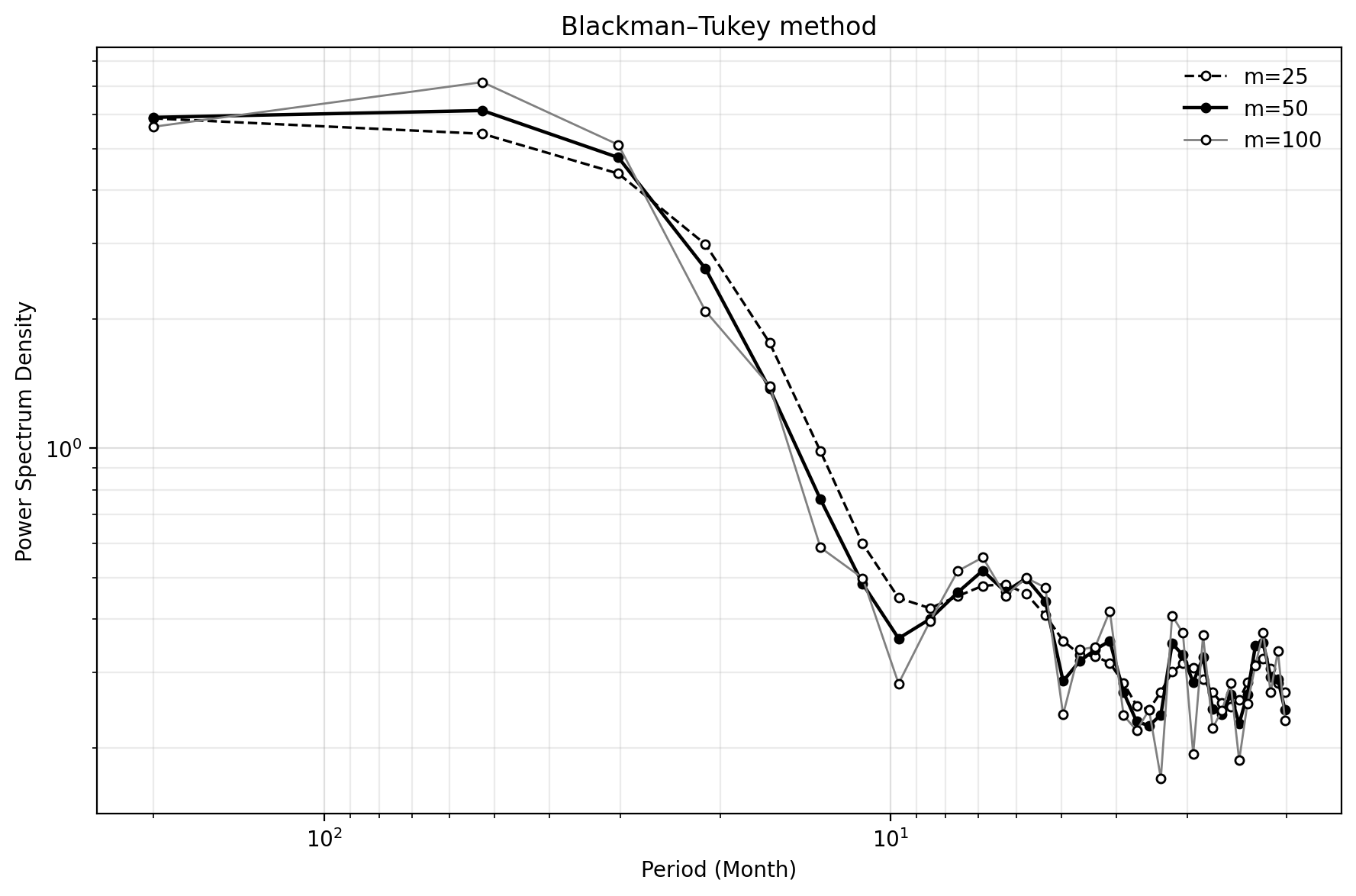
次に Blackman–Tukey 法でスペクトルを計算する。ここでの m_list = [25, 50, 100] は、最大ラグ m を3通り試す、という意味である。月平均データなので、それぞれ約2.1年、約4.2年、約8.3年先のラグまで自己共分散を使うことになる。
# -----------------------------
# BT法の設定
# -----------------------------
m_list = [25, 50, 100]
n_freq_bt = 4096
min_period_plot = 2
max_period_plot = 500
out_png_bt = "SOI_BlackmanTukey.png"
def autocovariance(x, max_lag):
"""
Biased autocovariance:
gamma(k) = (1/N) sum_{t=0}^{N-k-1} x[t] x[t+k]
"""
x = np.asarray(x, dtype=float)
N = len(x)
gam = np.zeros(max_lag + 1, dtype=float)
for k in range(max_lag + 1):
gam[k] = np.dot(x[:N-k], x[k:]) / N
return gam
def blackman_tukey_window(m):
"""
Blackman window on lag domain, length m+1 for k=0..m
"""
k = np.arange(m + 1, dtype=float)
w = 0.42 + 0.5 * np.cos(np.pi * k / m) + 0.08 * np.cos(2.0 * np.pi * k / m)
return w
def blackman_tukey_spectrum(x, m=50, n_freq=4096, dt=1.0):
"""
Blackman-Tukey spectral estimate
P(f) = dt * [ gamma(0) + 2 * sum_{k=1}^m w(k) gamma(k) cos(2 pi f k dt) ]
"""
x = np.asarray(x, dtype=float)
N = len(x)
if m >= N:
raise ValueError(f"m must be smaller than data length. m={m}, N={N}")
gamma = autocovariance(x, m)
w = blackman_tukey_window(m)
freq = np.linspace(1.0 / (n_freq * dt), 0.5 / dt, n_freq) # cycle/month
psd = np.zeros_like(freq)
psd += dt * gamma[0] * w[0]
for k in range(1, m + 1):
psd += 2.0 * dt * w[k] * gamma[k] * np.cos(2.0 * np.pi * freq * k * dt)
psd = np.maximum(psd, 1e-8)
period = 1.0 / freq
return {
"freq": freq,
"period": period,
"psd": psd,
"gamma": gamma,
"window": w
}
def plot_blackman_tukey_results(results_dict, start_year=None, end_year=None,
min_period_plot=2, max_period_plot=500):
fig, ax = plt.subplots(figsize=(10, 7))
styles = {
25: dict(ls='--', marker='o', mfc='white', mec='black', ms=4, lw=1.2, color='black'),
50: dict(ls='-', marker='o', mfc='black', mec='black', ms=4, lw=1.6, color='black'),
100:dict(ls='-', marker='o', mfc='white', mec='black', ms=4, lw=1.0, color='gray'),
}
for m, result in results_dict.items():
period = result["period"]
psd = result["psd"]
mask = (period >= min_period_plot) & (period <= max_period_plot)
idx = np.where(mask)[0]
step = max(1, len(idx) // 35)
idx_plot = idx[::step]
style = styles.get(m, dict(ls='-', marker='o', ms=4, lw=1.2, color='black'))
ax.loglog(period[idx_plot], psd[idx_plot],
linestyle=style["ls"],
marker=style["marker"],
markersize=style["ms"],
markerfacecolor=style["mfc"],
markeredgecolor=style["mec"],
linewidth=style["lw"],
color=style["color"],
label=f"m={m}")
ax.grid(True, which='major', alpha=0.4)
ax.grid(True, which='minor', alpha=0.25)
ax.set_xlabel("Period (Month)", fontsize=16)
ax.set_ylabel("Power Spectrum Density (hPa$^2$ x month)", fontsize=16)
ax.set_title(f"Blackman-Tukey Method\n({start_year}-{end_year})", fontsize=22)
ax.invert_xaxis()
ax.tick_params(labelsize=13)
ax.legend(fontsize=14, frameon=False, loc="upper right")
plt.tight_layout()
return fig, ax
bt_results = {}
for m_bt in m_list:
bt_results[m_bt] = blackman_tukey_spectrum(x, m=m_bt, n_freq=n_freq_bt, dt=1.0)
fig, ax = plot_blackman_tukey_results(
bt_results,
start_year=start_year,
end_year=end_year,
min_period_plot=min_period_plot,
max_period_plot=max_period_plot
)
if save_figure:
fig.savefig(out_png_bt, dpi=300, bbox_inches="tight")
print(f"Saved: {out_png_bt}")
plt.show()BT法コードの読み方
- autocovariance は、ラグごとの自己共分散を計算する。
- blackman_tukey_window は、ラグが大きい自己共分散の影響を弱める窓関数を作る。
- blackman_tukey_spectrum は、自己共分散と窓関数からスペクトルを作る。
- m_list を変えることで、最大ラグによるスペクトルの違いを見る。
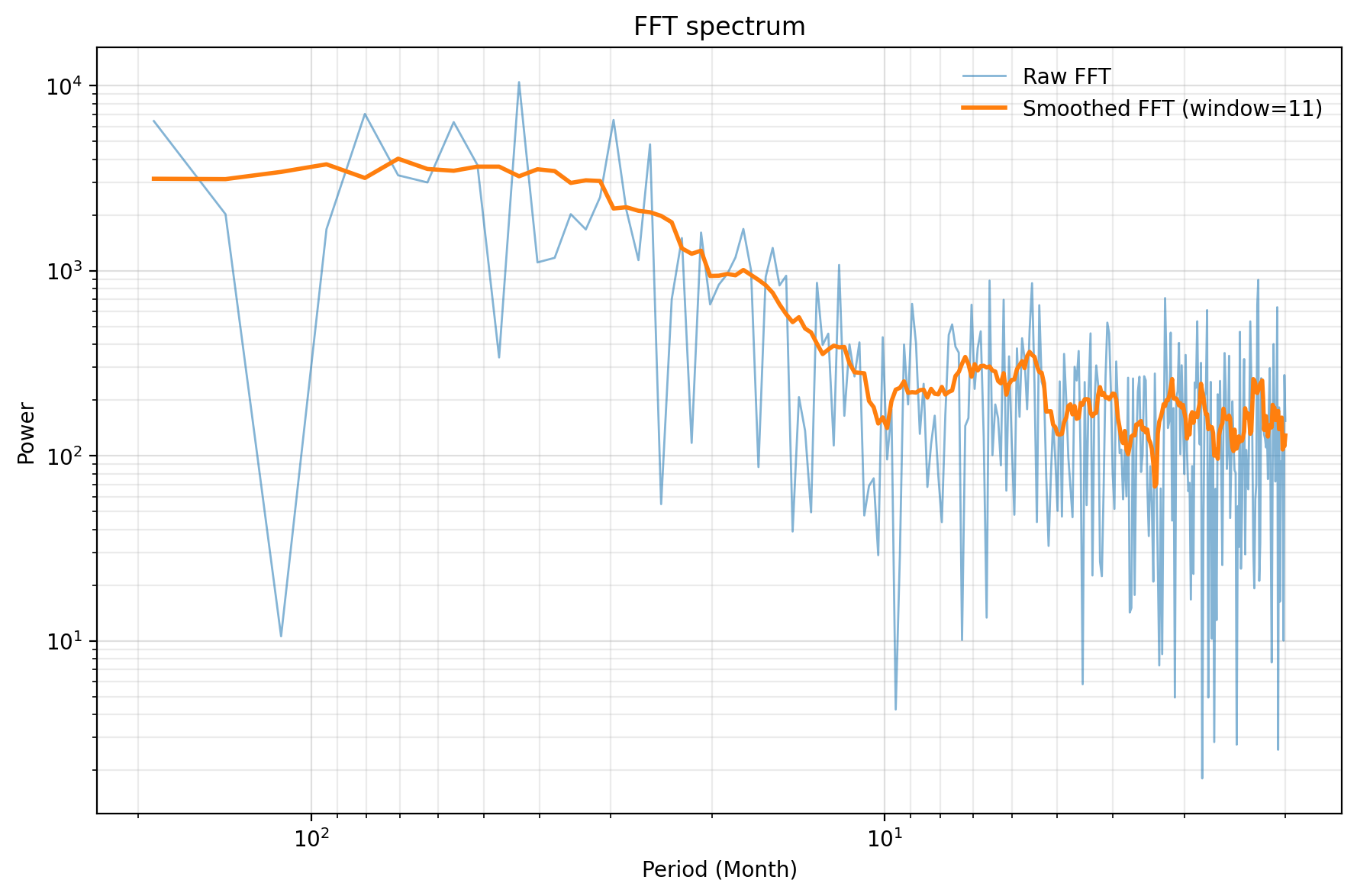
4.3 FFT法で計算&図
FFT法では、時系列を nseg=10 個に分割し、それぞれの FFT パワーを平均する。自由度はおおよそ 2*nseg = 20 と考える。
# -----------------------------
# FFT法の設定
# -----------------------------
nseg = 10
zero_padding_factor = 4
use_hann_window = False
out_png_fft = "FFTresult_python_style.png"
def compute_segment_averaged_fft(x, nseg=10, zero_padding_factor=4,
remove_mean=True, use_hann_window=False):
"""
時系列 x を nseg 個に分割して、それぞれのFFTパワーを平均する。
"""
x = np.asarray(x, dtype=float)
x = x[np.isfinite(x)]
if remove_mean:
x = x - np.mean(x)
N = len(x)
seglen = N // nseg
if seglen < 4:
raise ValueError("セグメント長が短すぎます。nsegを減らしてください。")
# 端数は切り捨て
x = x[:seglen * nseg]
dt = 1.0 # month
spectra = []
for i in range(nseg):
seg = x[i * seglen:(i + 1) * seglen].copy()
if remove_mean:
seg = seg - np.mean(seg)
if use_hann_window:
w = np.hanning(seglen)
seg = seg * w
norm = np.sum(w**2)
else:
norm = seglen
nfft_target = int(np.ceil(seglen * zero_padding_factor))
nfft = int(2 ** np.ceil(np.log2(nfft_target)))
fftv = np.fft.rfft(seg, n=nfft)
freq = np.fft.rfftfreq(nfft, d=dt)
psd = (np.abs(fftv) ** 2) * dt / norm
spectra.append(psd)
spectra = np.array(spectra)
psd_mean = np.mean(spectra, axis=0)
freq_nonzero = freq[1:]
psd_nonzero = psd_mean[1:]
period = 1.0 / freq_nonzero
return {
"freq": freq_nonzero,
"period": period,
"psd": psd_nonzero,
"nseg": nseg,
"dof": 2 * nseg
}
def plot_figurefft_style(result, point_index=9):
XX = result["period"]
Y = result["psd"]
nseg = result["nseg"]
dof = result["dof"]
chi975 = chi2.ppf(0.975, dof)
chi025 = chi2.ppf(0.025, dof)
y0 = Y[point_index]
x0 = XX[point_index]
err_upper = (nseg * y0) / chi025
err_lower = (nseg * y0) / chi975
fig, ax = plt.subplots(figsize=(10, 7))
ax.loglog(XX, Y, 'k-', lw=1.2)
ax.loglog([x0, x0], [err_lower, err_upper], 'ro-')
ax.grid(True, which='major', alpha=0.4)
ax.grid(True, which='minor', alpha=0.3)
ax.set_ylabel('Power Spectrum Density (hPa$^2$ x month)', fontsize=16)
ax.set_xlabel('Period (Month)', fontsize=16)
ax.set_title(f'FFT method (n={nseg}) applied to SOI timeseries with Zero padding',
fontsize=20)
ax.set_ylim(0.1, 100)
ax.tick_params(labelsize=13)
plt.tight_layout()
return fig, ax
fft_result = compute_segment_averaged_fft(
x,
nseg=nseg,
zero_padding_factor=zero_padding_factor,
remove_mean=remove_mean,
use_hann_window=use_hann_window
)
print(f"nseg = {fft_result['nseg']}")
print(f"dof = {fft_result['dof']}")
fig, ax = plot_figurefft_style(fft_result, point_index=9)
if save_figure:
fig.savefig(out_png_fft, dpi=300, bbox_inches="tight")
print(f"Saved: {out_png_fft}")
plt.show()FFTコードの読み方
- nseg=10 は、時系列を10個に分けて平均する指定である。
- np.fft.rfft は、実数時系列に対する片側FFTである。
- zero_padding_factor=4 により、各セグメント長の約4倍までゼロパディングする。
- chi2.ppf は、カイ二乗分布に基づく誤差幅を計算するために使っている。
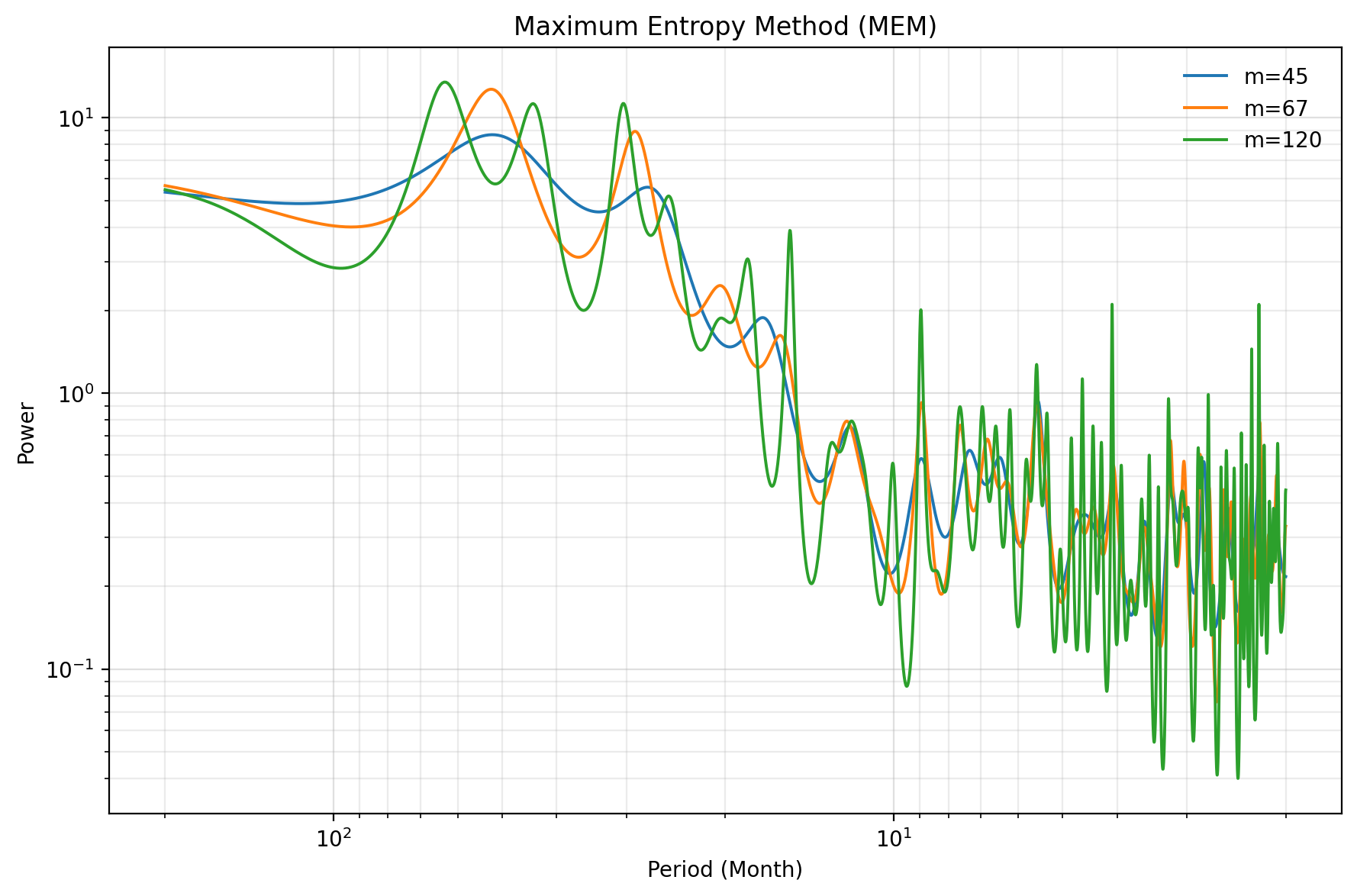
4.4 MEM法で計算&図
MEM法では、ARモデルの次数を m=67 とし、Levinson–Durbin 再帰で Yule–Walker 方程式を解く。
# -----------------------------
# MEM法の設定
# -----------------------------
m_mem = 67
n_freq_mem = 4096
peak_min_period = 2
peak_max_period = 120
n_top_peaks = 10
out_png_mem = f"SOI_MEM_m{m_mem}_{start_year}_{end_year}.png"
def levinson_durbin(gamma, order):
"""
Solve Yule-Walker equations using Levinson-Durbin recursion.
"""
gamma = np.asarray(gamma, dtype=float)
if gamma[0] <= 0:
raise ValueError("gamma[0] must be positive.")
a = np.zeros(order + 1, dtype=float)
e = gamma[0]
refl = np.zeros(order, dtype=float)
a[0] = 1.0
for k in range(1, order + 1):
acc = gamma[k]
for j in range(1, k):
acc += a[j] * gamma[k - j]
lam = -acc / e
refl[k - 1] = lam
a_new = a.copy()
for j in range(1, k):
a_new[j] = a[j] + lam * a[k - j]
a_new[k] = lam
a = a_new
e = e * (1.0 - lam**2)
if e <= 0:
raise ValueError("Non-positive prediction error variance encountered. Try smaller model order.")
return a, e, refl
def mem_spectrum(x, order=67, n_freq=4096, dt=1.0):
"""
Maximum Entropy / AR spectrum from Yule-Walker solution
"""
x = np.asarray(x, dtype=float)
N = len(x)
if order >= N:
raise ValueError(f"Model order must be smaller than data length. order={order}, N={N}")
gamma = autocovariance(x, order)
a, sigma2, refl = levinson_durbin(gamma, order)
freq = np.linspace(1.0 / (n_freq * dt), 0.5 / dt, n_freq)
den = np.ones_like(freq, dtype=complex)
for k in range(1, order + 1):
den += a[k] * np.exp(-2j * np.pi * freq * k * dt)
psd = sigma2 * dt / (np.abs(den) ** 2)
period = 1.0 / freq
return {
"freq": freq,
"period": period,
"psd": psd,
"a": a,
"sigma2": sigma2,
"refl": refl
}
def find_local_peaks(period, power, min_period=2, max_period=120, n_top=10):
mask = (period >= min_period) & (period <= max_period)
p = period[mask]
s = power[mask]
idx = []
for i in range(1, len(s) - 1):
if (s[i] > s[i - 1]) and (s[i] > s[i + 1]):
idx.append(i)
if len(idx) == 0:
return pd.DataFrame(columns=["Period_month", "Period_year", "Power"])
out = pd.DataFrame({
"Period_month": p[idx],
"Period_year": p[idx] / 12.0,
"Power": s[idx]
})
out = out.sort_values("Power", ascending=False).reset_index(drop=True)
return out.head(n_top)
def plot_mem_result(result, start_year=None, end_year=None,
min_period_plot=2, max_period_plot=500, order=67):
period = result["period"]
psd = result["psd"]
mask = (period >= min_period_plot) & (period <= max_period_plot)
fig, ax = plt.subplots(figsize=(10, 7))
ax.loglog(period[mask], psd[mask], 'k-', lw=1.2)
ax.grid(True, which='major', alpha=0.4)
ax.grid(True, which='minor', alpha=0.3)
ax.set_xlabel("Period (Month)", fontsize=16)
ax.set_ylabel("Power Spectrum Density (hPa$^2$ x month)", fontsize=16)
ax.set_title(f"Max entropy method (m={order}) applied to SOI timeseries\n({start_year}-{end_year})",
fontsize=20)
ax.tick_params(labelsize=13)
plt.tight_layout()
return fig, ax
mem_result = mem_spectrum(x, order=m_mem, n_freq=n_freq_mem, dt=1.0)
print(f"Prediction error variance sigma^2 = {mem_result['sigma2']:.6f}")
fig, ax = plot_mem_result(
mem_result,
start_year=start_year,
end_year=end_year,
min_period_plot=min_period_plot,
max_period_plot=max_period_plot,
order=m_mem
)
if save_figure:
fig.savefig(out_png_mem, dpi=300, bbox_inches="tight")
print(f"Saved figure: {out_png_mem}")
plt.show()
peaks = find_local_peaks(
mem_result["period"],
mem_result["psd"],
min_period=peak_min_period,
max_period=peak_max_period,
n_top=n_top_peaks
)
print("Top MEM peaks")
display(peaks)MEMコードの読み方
- levinson_durbin は、自己共分散からAR係数を求める再帰計算である。
- mem_spectrum は、AR係数と予測誤差分散からMEMスペクトルを計算する。
- find_local_peaks は、MEMスペクトルの局所ピークを探す。
- m_mem=67 は、ARモデルの次数であり、結果に強く影響する。
4.5 最後に3つの手法の比較
最後に、BT法、FFT法、MEM法を同じ図に重ねる。絶対値のスケールは手法によって異なるので、ここでは最大値で規格化して、ピークの位置を比較する。
# -----------------------------
# 3手法の比較図
# -----------------------------
def normalize_for_plot(y):
y = np.asarray(y, dtype=float)
y = np.maximum(y, 1e-12)
return y / np.nanmax(y)
fig, ax = plt.subplots(figsize=(10, 7))
# BT法は代表として m=50 を使う
bt = bt_results[50]
mask_bt = (bt["period"] >= min_period_plot) & (bt["period"] <= max_period_plot)
ax.loglog(bt["period"][mask_bt], normalize_for_plot(bt["psd"][mask_bt]),
color="black", lw=1.8, label="Blackman-Tukey (m=50)")
# FFT法
mask_fft = (fft_result["period"] >= min_period_plot) & (fft_result["period"] <= max_period_plot)
ax.loglog(fft_result["period"][mask_fft], normalize_for_plot(fft_result["psd"][mask_fft]),
color="gray", lw=1.5, label=f"FFT (nseg={nseg})")
# MEM法
mask_mem = (mem_result["period"] >= min_period_plot) & (mem_result["period"] <= max_period_plot)
ax.loglog(mem_result["period"][mask_mem], normalize_for_plot(mem_result["psd"][mask_mem]),
color="dimgray", lw=1.2, linestyle="--", label=f"MEM (m={m_mem})")
ax.grid(True, which="major", alpha=0.4)
ax.grid(True, which="minor", alpha=0.25)
ax.set_xlabel("Period (Month)", fontsize=16)
ax.set_ylabel("Normalized spectral power", fontsize=16)
ax.set_title("Comparison of three spectral methods", fontsize=20)
ax.invert_xaxis()
ax.legend(frameon=False, fontsize=13)
ax.tick_params(labelsize=13)
plt.tight_layout()
plt.show()比較図で注意すること
- BT法、FFT法、MEM法では、スペクトルの絶対値の定義が完全には同じではない。
- そのため、比較図では normalize_for_plot により最大値を1にそろえる。
- この図で見るべきなのは、パワーの絶対値ではなく、ピークがどの周期に出るかである。
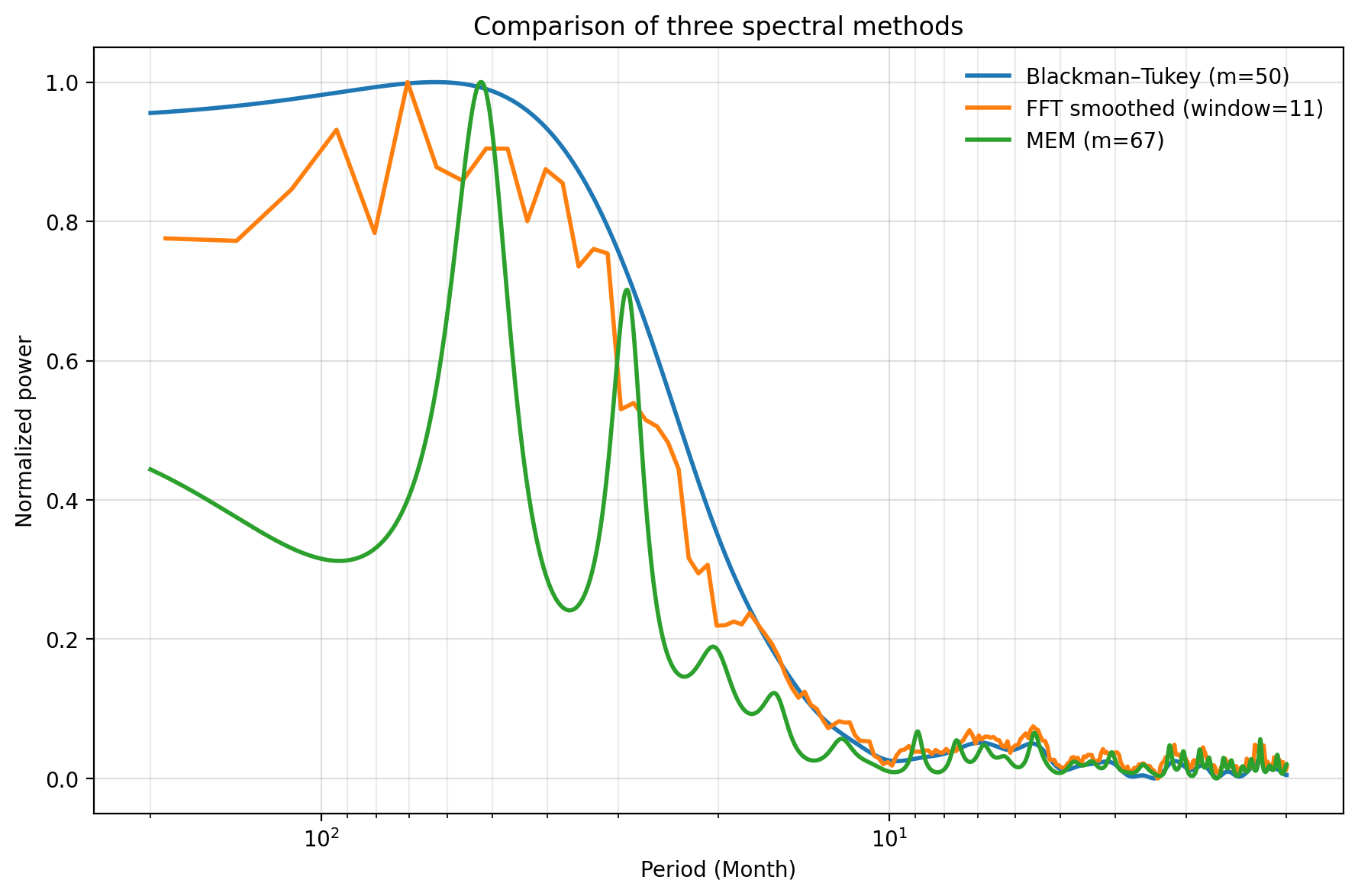
どう解釈するか
スペクトル図では、横軸が周期、縦軸がその周期の変動の強さを表す。横軸を周期で表示しているため、値が大きいほど長周期、値が小さいほど短周期である。
SOI のような ENSO に関係する時系列では、数年スケールの変動が重要である。したがって、数十か月から数年程度の範囲にピークがあるかを確認する。
| 見方 | 解釈 |
|---|---|
| 3手法で同じ周期帯に山がある | 比較的信頼できる卓越周期と考えやすい。 |
| MEMだけに鋭いピークがある | ARモデル次数に由来する可能性があるため、慎重に扱う。 |
| BT法では山が丸い | 窓掛けにより安定化されているが、分解能は下がっている。 |
| FFTがギザギザしている | 有限長時系列の影響や分割平均の限界を反映している。 |
まとめ
- BT法は、自己共分散を経由してスペクトルを推定する方法である。
- FFT法は、時系列を周波数成分に直接分解する基本的な方法である。
- MEM法は、ARモデルに基づく方法で、鋭いピークを出しやすい。
- 3つの方法は同じデータを使っても見え方が異なる。
- 解釈では、単一のピークではなく、複数手法で共通して見える周期帯に注目する。