1. この回でやること
前回までに SOI を計算し、移動平均や自己相関からその時間変動を見てきた。今回は、SOI を 大気側の指標、El Niño 監視海域の SST anomaly を 海洋側の指標 とみなし、両者の関係を調べる。
- SOI 時系列と SST anomaly を読み込む
- 共通期間だけを取り出す
- NINO1+2, NINO3, NINO4, NINO3.4 の各海域について相関係数を求める
- 最も関係の強い海域について回帰式と決定係数を求める
- 散布図と回帰直線を描き、画像として保存する
- ラグ相関を計算し、フィルタなし・13か月移動平均後・比較図を作る
2. 相関係数・回帰式・決定係数とは何か
2.1 相関係数
相関係数は、2つの変数がどれくらい一緒に増減するかを表す量である。値は -1 から 1 の範囲をとる。
ここで cov(X, Y) は共分散、σ は標準偏差である。共分散だけだと単位に依存するので、標準偏差で割って無次元化している。
2.2 最小二乗法による回帰式
SST anomaly を説明変数 X、SOI を目的変数 Y として、
の形の直線を求める。最小二乗法では、観測値と回帰直線の差の二乗和が最小になるように a と b を決める。
2.3 決定係数
決定係数 R² は、その回帰式がどれだけ当てはまっているかを表す指標である。ここで大事なのは、何と何の差を二乗して足しているのかである。
TSS:もとの SOI のばらつき
TSS は Total Sum of Squares の略で、日本語では全平方和という。これは、SOI の観測値 y が、SOI の平均値 ȳ からどれくらいばらついているかを表す。
つまり、回帰式を使わずに「SOI は平均値のまわりでどれくらい変動しているか」を測っている。
SSR:回帰直線で説明できなかった残り
SSR はここでは Residual Sum of Squares、つまり残差平方和として使っている。まず回帰式から予測値 ŷ を計算する。
そして、実際の SOI y と、回帰式で予測した SOI ŷ の差を二乗して足す。
この値が小さいほど、回帰直線が観測値に近い。つまり、SST anomaly から SOI をよく説明できていることになる。
Pythonコードとの対応
y_pred = a * x + b
ss_res = np.sum((y - y_pred) ** 2)
ss_tot = np.sum((y - np.mean(y)) ** 2)
r2 = 1 - ss_res / ss_tot| Python の変数 | 数式 | 意味 |
|---|---|---|
| y | yᵢ | 実際の SOI |
| x | xᵢ | SST anomaly |
| y_pred | ŷᵢ = axᵢ + b | 回帰式から予測した SOI |
| ss_res | Σ(yᵢ - ŷᵢ)² | 回帰直線で説明できなかった残り |
| ss_tot | Σ(yᵢ - ȳ)² | もとの SOI 全体のばらつき |
したがって ss_res / ss_tot は、「もとのばらつきのうち、回帰式で説明しきれずに残った割合」を表す。そこを 1 から引くことで、「回帰式で説明できた割合」が R² になる。
| 量 | 意味 |
|---|---|
| 相関係数 r | 2つの変数の増減の向きと強さ |
| 回帰式 Y = aX + b | X から Y を近似する直線 |
| 決定係数 R² | その直線がどれだけ当てはまるか |
3. 使うデータと注意点
今回は 2 つのファイルを使う。
- SOI_timeseries_updated.txt:前回までに作成した SOI 時系列
- sstoi.indices:El Niño 監視海域の SST と anomaly
注意すべきことは、SOI のデータは 2025 年 3 月までであり、SST 側はそれ以降まで含む場合があることである。したがって、解析には必ず 共通期間だけ を使う。
4. SOI と SST データを読む
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# =========================================================
# 1. データ読み込み
# =========================================================
soi_df = pd.read_csv("SOI_timeseries_updated.txt", sep=______)
soi_df = soi_df.dropna(subset=[______]).reset_index(drop=True)
soi_df["DATE"] = pd.to_datetime(dict(
year=soi_df[______].astype(int),
month=soi_df[______].astype(int),
day=1
))
sst_df = pd.read_csv("sstoi.indices", sep=______, engine=______)
print("SST columns:")
print(sst_df.columns)
sst_df["DATE"] = pd.to_datetime(dict(
year=sst_df[______].astype(int),
month=sst_df[______].astype(int),
day=1
))穴埋めにした理由
- 空白区切りファイルの読み方
- 欠損値を落とす列の指定
- YEAR/MONTH と YR/MON の違い
- 日付列を作る意味
5. SST anomaly列を整理し、共通期間にそろえる
SST ファイルでは anomaly 列が ANOM, ANOM.1, ANOM.2, ANOM.3 のように並んでいる。列名を読み替え、SOI と日付で結合する。
# =========================================================
# 2. SST anomaly 列を整理
# このファイルでは anomaly 列が ANOM, ANOM.1, ...
# =========================================================
sst_use = sst_df[[
"DATE",
______, # NINO1+2 anomaly
______, # NINO3 anomaly
______, # NINO4 anomaly
______ # NINO3.4 anomaly
]].copy()
sst_use = sst_use.rename(columns={
______: "NINO1+2_ANOM",
______: "NINO3_ANOM",
______: "NINO4_ANOM",
______: "NINO3.4_ANOM"
})
# =========================================================
# 3. 共通期間で結合
# SOIが2025年3月までなので、共通部分だけを使う
# =========================================================
df = pd.merge(soi_df, sst_use, on=______, how=______)
print("\n共通期間")
print("start:", df[______].min())
print("end :", df[______].max())
print("N :", len(df))ここでのポイント:結合方法を自分で選ぶ
rename(columns={...}) は、列名を分かりやすく変更するために使う。ここでは、元データ中の ANOM, ANOM.1, ANOM.2, ANOM.3 を、それぞれの海域名が分かる列名に変えている。
pd.merge() で指定する主なオプション
pd.merge() は、2つの表を「どの列を手がかりにするか」と「どの範囲を残すか」を指定して結合する関数である。
| オプション | 使い方 | 意味 | 今回使えるか |
|---|---|---|---|
| on | on="列名" | 左右の表に同じ名前の列があるとき、その列を手がかりに結合する | 使える |
| on | on=["列1", "列2"] | 複数の列を組み合わせて結合する。例:年と月を別々に使う | 使えるが、今回は日付列を作ったので不要 |
| left_on, right_on | left_on="A", right_on="B" | 左右の表で列名が違うときに使う | 列名が同じなら不要 |
| left_index, right_index | left_index=True, right_index=True | 列ではなくインデックスを手がかりに結合する | 今回は日付を列として持っているので不要 |
how で選ぶ結合方法
| how の値 | 残るデータ | SOI と SST の比較で起こること |
|---|---|---|
| "inner" | 両方の表に存在する日付だけ | SOI と SST が両方ある月だけで解析できる |
| "left" | 左側の表、ここでは soi_df の日付をすべて残す | SOI だけある月では SST が欠損になる |
| "right" | 右側の表、ここでは sst_use の日付をすべて残す | SST だけある月では SOI が欠損になる |
| "outer" | どちらか一方に存在する日付をすべて残す | 共通しない月が残り、どちらかの値が欠損になる |
| "cross" | すべての組み合わせを作る | 時系列の月ごとの対応が崩れるので、今回の解析には使わない |
今回の目的は、同じ月の SOI と SST anomaly を対応させて相関を計算することである。片方にしか存在しない月は、相関や回帰には使えない。
- SOI 側にも SST 側にも作った、共通の時刻情報を持つ列はどれか。
- SOI と SST の両方が存在する月だけを残すには、どの how を選べばよいか。
# 試しに結合方法ごとの行数を比べてみる
for method in ["inner", "left", "right", "outer"]:
tmp = pd.merge(soi_df, sst_use, on="DATE", how=method)
print(method, tmp.shape)6. 各海域の相関係数・回帰式・決定係数
まずは 1 つの関数にまとめて、どの海域が最も SOI と強く結びついているかを調べる。
# =========================================================
# 4. 相関・回帰・決定係数を計算する関数
# =========================================================
def calc_stats(x, y):
x = np.asarray(x, dtype=______)
y = np.asarray(y, dtype=______)
mask = np.isfinite(x) & np.isfinite(y)
x = x[______]
y = y[______]
# 相関係数
# np.corrcoef(x, y) は 2×2 の相関係数行列を返す
corr_matrix = np.corrcoef(x, y)
r = corr_matrix[______, ______]
# 回帰式 y = a x + b
a, b = np.polyfit(x, y, ______)
# 決定係数
# y_pred は、回帰式から予測した SOI
y_pred = a * x + b
# ss_res は、実際の SOI と予測 SOI の差の二乗和
# つまり、回帰直線で説明できなかった残り
ss_res = np.sum((y - y_pred) ** ______)
# ss_tot は、実際の SOI と SOI 平均値の差の二乗和
# つまり、もとの SOI 全体のばらつき
ss_tot = np.sum((y - np.mean(y)) ** ______)
# 1 から「説明できなかった割合」を引く
r2 = 1 - ss_res / ss_tot
return r, a, b, r2, x, y, y_prednp.corrcoef(x, y) の意味
ここで np.corrcoef() が初めて出てくる。これは相関係数を 1 個だけ返すのではなく、2×2 の相関係数行列を返す関数である。
corr_matrix = np.corrcoef(x, y)
print(corr_matrix)出力は概念的には次のような形になる。
[[1.0, r],
[r, 1.0]]| 取り出す位置 | 意味 |
|---|---|
| corr_matrix[0, 0] | x と x の相関。自分自身との相関なので必ず 1。 |
| corr_matrix[1, 1] | y と y の相関。自分自身との相関なので必ず 1。 |
| corr_matrix[0, 1] | x と y の相関。今回ほしい値。 |
| corr_matrix[1, 0] | y と x の相関。値は [0, 1] と同じ。 |
関数の中では出力が多くなりすぎるので毎回は表示しないが、1つの海域だけで試すなら次のように確認できる。
x_test = df["NINO3.4_ANOM"].to_numpy()
y_test = df["SOI"].to_numpy()
mask_test = np.isfinite(x_test) & np.isfinite(y_test)
print(np.corrcoef(x_test[mask_test], y_test[mask_test]))ss_res と ss_tot の見方
- y は実際に観測された SOI。
- y_pred は SST anomaly から回帰式で予測した SOI。
- ss_res は y - y_pred の二乗和なので、予測から外れた量。
- ss_tot は y - np.mean(y) の二乗和なので、SOI そのものの全体のばらつき。
- r2 は「全体のばらつきのうち、回帰直線で説明できた割合」と読む。
# =========================================================
# 5. 各海域で相関・回帰・決定係数
# =========================================================
regions = [______, ______, ______, ______]
results = []
for region in regions:
r, a, b, r2, x_valid, y_valid, y_pred = calc_stats(df[region], df[______])
results.append({
"Region": region,
"Correlation_r": r,
"Slope_a": a,
"Intercept_b": b,
"R2": r2
})
result_df = pd.DataFrame(results)
print("\n各海域の結果")
print(result_df)
# 相関係数 r は正にも負にもなる。
# ここでは「正か負か」ではなく、「関係の強さ」を比べたい。
# そのため、相関係数の絶対値を abs_r という新しい列に入れる。
result_df["abs_r"] = result_df["Correlation_r"].______()
# abs_r を基準に並べ替える。
# ascending=True なら小さい順に並ぶ。
# ascending=False なら大きい順に並ぶ。
# 今回の目的に合う方を選ぶ。
result_df = result_df.sort_values("abs_r", ascending=______).reset_index(drop=True)
print("\n相関の強い順")
print(result_df[["Region", "Correlation_r", "R2"]])なぜ絶対値をとって並べ替えるのか
ここで知りたいのは、4つの NINO 海域のうち、SOI と最も強く関係している海域はどれかである。
相関係数 r は -1 から 1 の値をとる。正の相関では一方が増えるともう一方も増え、負の相関では一方が増えるともう一方は減る。
| 相関係数 | 関係の向き | 関係の強さ |
|---|---|---|
| r = 0.8 | 強い正の相関 | |r| = 0.8 |
| r = -0.8 | 強い負の相関 | |r| = 0.8 |
| r = -0.2 | 弱い負の相関 | |r| = 0.2 |
つまり、r = -0.8 は数値としては r = -0.2 より小さいが、関係はずっと強い。したがって、関係の強さを比較するときは符号を外した abs_r = |r| を使う。
次に、sort_values("abs_r", ascending=...) を使って、abs_r を基準に表を並べ替える。
| ascending の指定 | 並び方 | 今回の表で起こること |
|---|---|---|
| ascending=True | 小さい順 | abs_r が小さい海域、つまり相関が弱い海域から上に並ぶ。 |
| ascending=False | 大きい順 | abs_r が大きい海域、つまり相関が強い海域から上に並ぶ。 |
- r = -0.75 と r = 0.40 では、どちらが SOI と強く関係しているか。
- 相関の向きも知りたいとき、表示するべき列は abs_r か、それとも元の Correlation_r か。
- 今回は「SOI と関係が強い海域」を表の上に出したい。ascending には True と False のどちらを入れるべきか。
7. 散布図と回帰直線
最も相関の強い海域として NINO3.4 を選び、SOI との散布図を描く。06CompSOIandSST.html と合わせるため、図を nino34_soi.png として保存する。
# =========================================================
# 6. NINO3.4 の散布図と回帰直線
# =========================================================
target = ______
r, a, b, r2, x_valid, y_valid, y_pred = calc_stats(df[target], df[______])
plt.figure(figsize=(6, 6))
plt.scatter(x_valid, y_valid, alpha=______)
xx = np.linspace(np.min(x_valid), np.max(x_valid), 100)
yy = a * xx + b
plt.plot(xx, yy, linewidth=2)
plt.xlabel("NINO3.4 SST anomaly")
plt.ylabel("SOI")
plt.title("NINO3.4 anomaly vs SOI")
plt.grid(True, alpha=0.3)
plt.text(
0.05, 0.95,
f"r = {r:.2f}\nR² = {r2:.2f}\nSOI = {a:.2f} × SST + {b:.2f}",
transform=plt.gca().transAxes,
verticalalignment="top"
)
plt.tight_layout()
plt.savefig(______, dpi=______)
plt.show()実際の結果を以下に示す。
図:NINO3.4 と SOI の関係
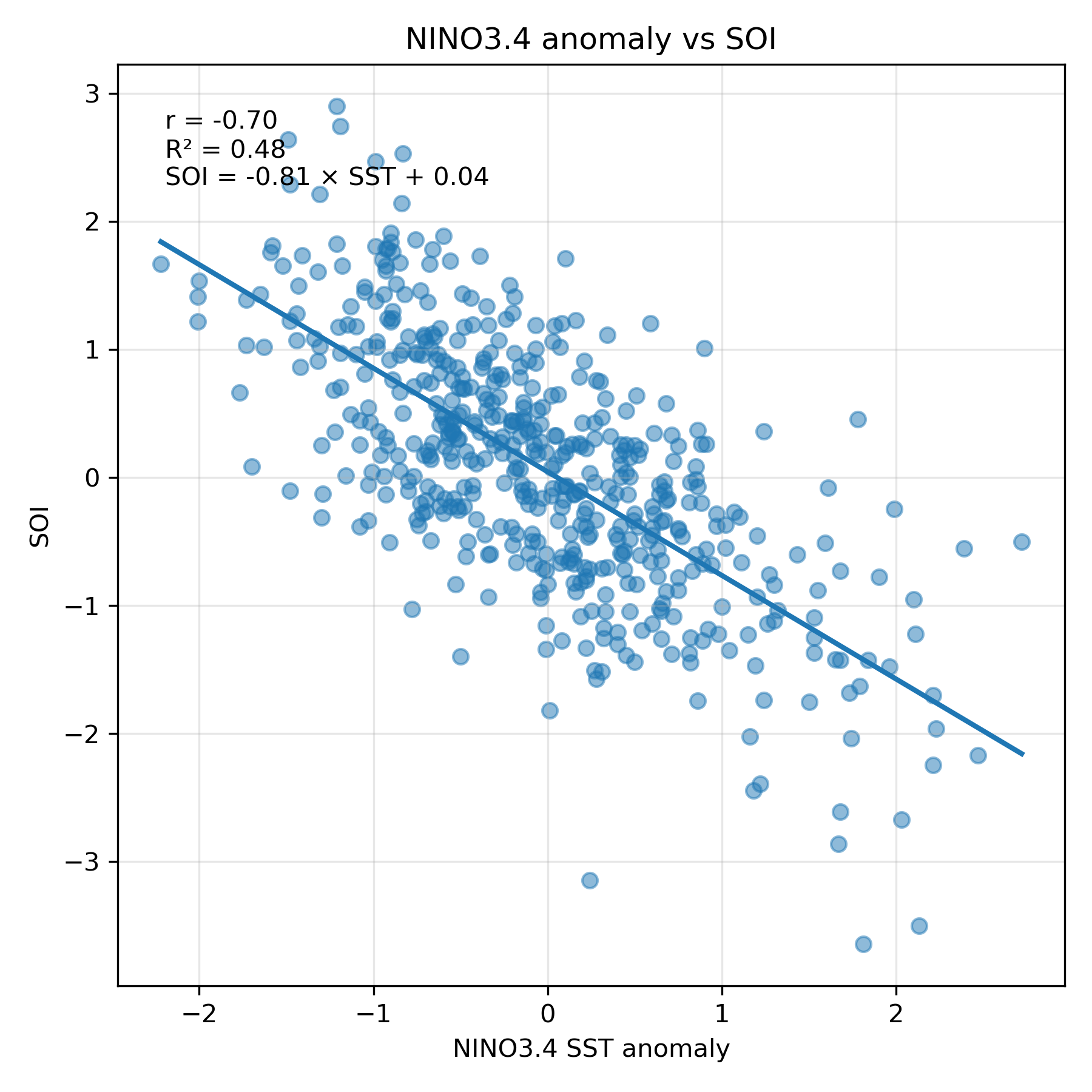
図:NINO3.4 海面水温偏差と SOI の散布図および回帰直線
- なぜ相関係数は負になりやすいのか
- 回帰直線の傾きが負とはどういう意味か
- R² が 1 に近くないのはなぜか
8. ラグ相関用関数
SST と SOI を時間的にずらしながら相関を求める。ここでは lag < 0 なら SOI が先行、lag > 0 なら SST が先行と読む。
# =========================================================
# 7. ラグ相関用関数
# =========================================================
def moving_average(x, window):
return pd.Series(x).rolling(window=window, center=______).mean().to_numpy()
def cross_correlation(x, y, max_lag):
"""
x = SST
y = SOI
lag < 0 : SOI が先行
lag > 0 : SST が先行
"""
x = np.asarray(x, dtype=float)
y = np.asarray(y, dtype=float)
# 調べるラグの一覧を作る。
# 例:max_lag=24 なら -24 から +24 か月まで。
lags = np.arange(-max_lag, max_lag + 1)
# 各ラグの相関係数を入れる配列を先に作る。
# まだ計算していない場所、または計算できない場所には何を入れておくべきか。
cc = np.full(len(lags), ______)
for i, lag in enumerate(lags):
if lag < 0:
x1 = x[-lag:]
y1 = y[:len(y) + lag]
elif lag > 0:
x1 = x[:len(x) - lag]
y1 = y[lag:]
else:
x1 = x
y1 = y
# x1 と y1 の両方が有限値である場所だけを使う。
mask = np.isfinite(x1) & np.isfinite(y1)
# 相関係数を計算するには、有効なペアが十分に必要である。
# 何個より多ければ計算することにするか。
if np.sum(mask) > ______:
cc[i] = np.corrcoef(x1[mask], y1[mask])[0, 1]
return lags, cccc = np.full(len(lags), ...) で何を入れておくか
cc は、それぞれのラグにおける相関係数を入れるための配列である。最初の段階ではまだ相関係数を計算していないので、仮の値で埋めておく必要がある。
| 候補 | 意味 | 今回の使いやすさ |
|---|---|---|
| 0 | 相関係数 0 として初期化する | 計算できなかった場所も「相関なし」に見えてしまうので不適切 |
| np.nan | 欠損値として初期化する | 計算できなかった場所を欠損として扱えるので適切 |
| 1 | 相関係数 1 として初期化する | 強い正相関があるように見えてしまうので不適切 |
したがって、ここでは「まだ計算していない、または計算できない値」を表すものを選ぶ。
if np.sum(mask) > ... の意味
mask は、SST と SOI の両方が有効な値である場所を True にする配列である。したがって、np.sum(mask) は「相関計算に使えるデータの組が何個あるか」を表す。
| 候補 | 意味 | 問題点 |
|---|---|---|
| > 0 | 有効なペアが1個でもあれば計算する | 1点だけでは相関係数は意味を持たない |
| > 1 | 有効なペアが2個以上なら計算する | 2点だけでは相関が極端になりやすく、安定しない |
| > 2 | 有効なペアが3個以上なら計算する | 最低限の条件としては安全。 |
今回の目的は、ラグを変えながら相関係数を計算することである。相関を計算できない場所は欠損として残し、有効なデータ数が少なすぎる場所では計算しないようにしたい。
- 計算できない場所を 0 として扱うと、結果の解釈にどんな問題が起きるか。
- 有効なデータが1個だけのとき、相関係数を計算してよいか。
- このコードでは、有効なペアが何個以上あるときに相関を計算する設定にすべきか。
9. ラグ相関(フィルタなし)
ここでは、平滑化をかけない元の時系列を使って、NINO3.4 の SST anomaly と SOI のラグ相関を計算する。
# =========================================================
# 8. ラグ相関(フィルタなし)
# =========================================================
# x は SST anomaly、y は SOI として使う。
# どの列を取り出すべきかを考える。
x_raw = df[______].to_numpy()
y_raw = df[______].to_numpy()
# 欠損値や無限大を除き、SST と SOI の両方が有効な月だけを残す。
mask_raw = np.isfinite(x_raw) & np.isfinite(y_raw)
x_raw = x_raw[mask_raw]
y_raw = y_raw[mask_raw]
# 何か月前後までずらして調べるかを指定する。
lags_raw, cc_raw = cross_correlation(x_raw, y_raw, max_lag=______)
# 最も強い負相関を探す。
# SOI と SST は負の相関になりやすいので、最小値を探す。
imin_raw = np.nanargmin(cc_raw)
lag_min_raw = lags_raw[______]
corr_min_raw = cc_raw[______]
print("\n【フィルタなし】")
print(f"最も強い負相関: lag = {lag_min_raw}, r = {corr_min_raw:.3f}")フィルタなしラグ相関で確認すること
ここでは、まだ移動平均をかけていない元の時系列を使う。したがって、月ごとの短周期変動も含んだまま、SST と SOI の時間差のある関係を見ることになる。
| コード | 意味 |
|---|---|
| df[...].to_numpy() | DataFrame の列を NumPy 配列に変換する。相関関数に渡しやすくするため。 |
| mask_raw | SST と SOI の両方が有効な値である月だけを選ぶための条件。 |
| max_lag | 前後何か月までずらして相関を見るかを決める。 |
| np.nanargmin(cc_raw) | 欠損値 np.nan を無視して、相関係数が最も小さい場所を探す。 |
なぜ np.nanargmin() を使うのか
SOI と NINO3.4 の SST anomaly は、一般に負の相関を示しやすい。そこで、ここでは「最も強い負相関」を探すため、相関係数 cc_raw の中で最も小さい値の位置を探している。
ただし、cc_raw には、相関を計算できなかった場所として np.nan が入る可能性がある。そのため、単純な np.argmin() ではなく、欠損値を無視できる np.nanargmin() を使う。
- x_raw には SST anomaly を入れる。今回はどの列を使うか。
- y_raw には大気側の指標を入れる。どの列を使うか。
- max_lag=24 とすると、何か月前後まで調べることになるか。
- imin_raw は最小値の位置番号である。最小相関のラグと相関係数を取り出すには、どこに入れればよいか。
10. ラグ相関(13か月移動平均後)
生データのままだと月ごとのゆらぎが大きいので、13か月移動平均をかけた後でもラグ相関を求める。ここでは 121か月移動平均は使わず、短周期のノイズを弱めるための 13か月平滑化だけを使う。
# =========================================================
# 9. ラグ相関(13か月移動平均)
# =========================================================
x_smooth = moving_average(df[______].to_numpy(), ______)
y_smooth = moving_average(df[______].to_numpy(), ______)
mask_smooth = np.isfinite(x_smooth) & np.isfinite(y_smooth)
x_smooth = x_smooth[mask_smooth]
y_smooth = y_smooth[mask_smooth]
lags_smooth, cc_smooth = cross_correlation(x_smooth, y_smooth, max_lag=______)
imin_smooth = np.nanargmin(cc_smooth)
lag_min_smooth = lags_smooth[imin_smooth]
corr_min_smooth = cc_smooth[imin_smooth]
print("\n【13か月移動平均後】")
print(f"最も強い負相関: lag = {lag_min_smooth}, r = {corr_min_smooth:.3f}")11. フィルタなし単独図
06CompSOIandSST.html と完全に対応させるため、まずフィルタなしのラグ相関だけを単独で確認する。
# =========================================================
# 10. フィルタなし単独図
# =========================================================
plt.figure(figsize=(7, 5))
plt.plot(lags_raw, cc_raw, linewidth=1.8)
plt.axhline(0, color="k", linewidth=0.8)
plt.axvline(0, color="k", linewidth=0.8)
plt.scatter(lag_min_raw, corr_min_raw, s=70)
plt.text(lag_min_raw, corr_min_raw,
f" lag={lag_min_raw}\n r={corr_min_raw:.2f}",
va="bottom", ha="left")
plt.xlabel("Lag (month)")
plt.ylabel("Correlation")
plt.title("Cross-correlation SST vs SOI (Raw)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()12. 13か月移動平均後単独図
次に、13か月移動平均後のラグ相関だけを単独で確認する。
# =========================================================
# 11. 13か月移動平均後単独図
# =========================================================
plt.figure(figsize=(7, 5))
plt.plot(lags_smooth, cc_smooth, linewidth=1.8)
plt.axhline(0, color="k", linewidth=0.8)
plt.axvline(0, color="k", linewidth=0.8)
plt.scatter(lag_min_smooth, corr_min_smooth, s=70)
plt.text(lag_min_smooth, corr_min_smooth,
f" lag={lag_min_smooth}\n r={corr_min_smooth:.2f}",
va="bottom", ha="left")
plt.xlabel("Lag (month)")
plt.ylabel("Correlation")
plt.title("Cross-correlation (13-month smoothed)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()13. フィルタ前後の比較
最後に、フィルタなしと 13か月移動平均後のラグ相関を 1 枚に重ねて描く。06CompSOIandSST.html と合わせるため、図を sst_soi_lagcor.png として保存する。
# =========================================================
# 12. フィルタなし vs フィルタ後 比較図
# =========================================================
plt.figure(figsize=(8, 6))
# raw
plt.plot(lags_raw, cc_raw, linestyle="--", color="tab:blue", label="Raw")
# smoothed
plt.plot(lags_smooth, cc_smooth, color="tab:orange", linewidth=2, label="13-month smoothed")
plt.axhline(0, color="k", linewidth=0.8)
plt.axvline(0, color="k", linewidth=0.8)
# 最小点
plt.scatter(lag_min_raw, corr_min_raw, color="tab:blue", s=70, zorder=3)
plt.scatter(lag_min_smooth, corr_min_smooth, color="tab:orange", s=70, zorder=3)
# raw の注釈(青)
plt.annotate(
f"raw\nlag={lag_min_raw}\nr={corr_min_raw:.2f}",
xy=(lag_min_raw, corr_min_raw),
xytext=(lag_min_raw - 8, corr_min_raw - 0.12),
arrowprops=dict(arrowstyle="->", color="tab:blue"),
color="tab:blue",
fontsize=12
)
# smoothed の注釈(オレンジ): Lag=10 付近に置く
plt.annotate(
f"smoothed\nlag={lag_min_smooth}\nr={corr_min_smooth:.2f}",
xy=(lag_min_smooth, corr_min_smooth),
xytext=(10, corr_min_smooth + 0.40),
arrowprops=dict(arrowstyle="->", color="tab:orange"),
color="tab:orange",
fontsize=12
)
plt.xlabel("Lag (month)")
plt.ylabel("Correlation")
plt.title("Cross-correlation (Raw vs Smoothed)")
plt.legend(loc="lower left")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(______, dpi=______)
plt.show()計算結果を図で確認する。
図:ラグ相関(Raw vs Smoothed)
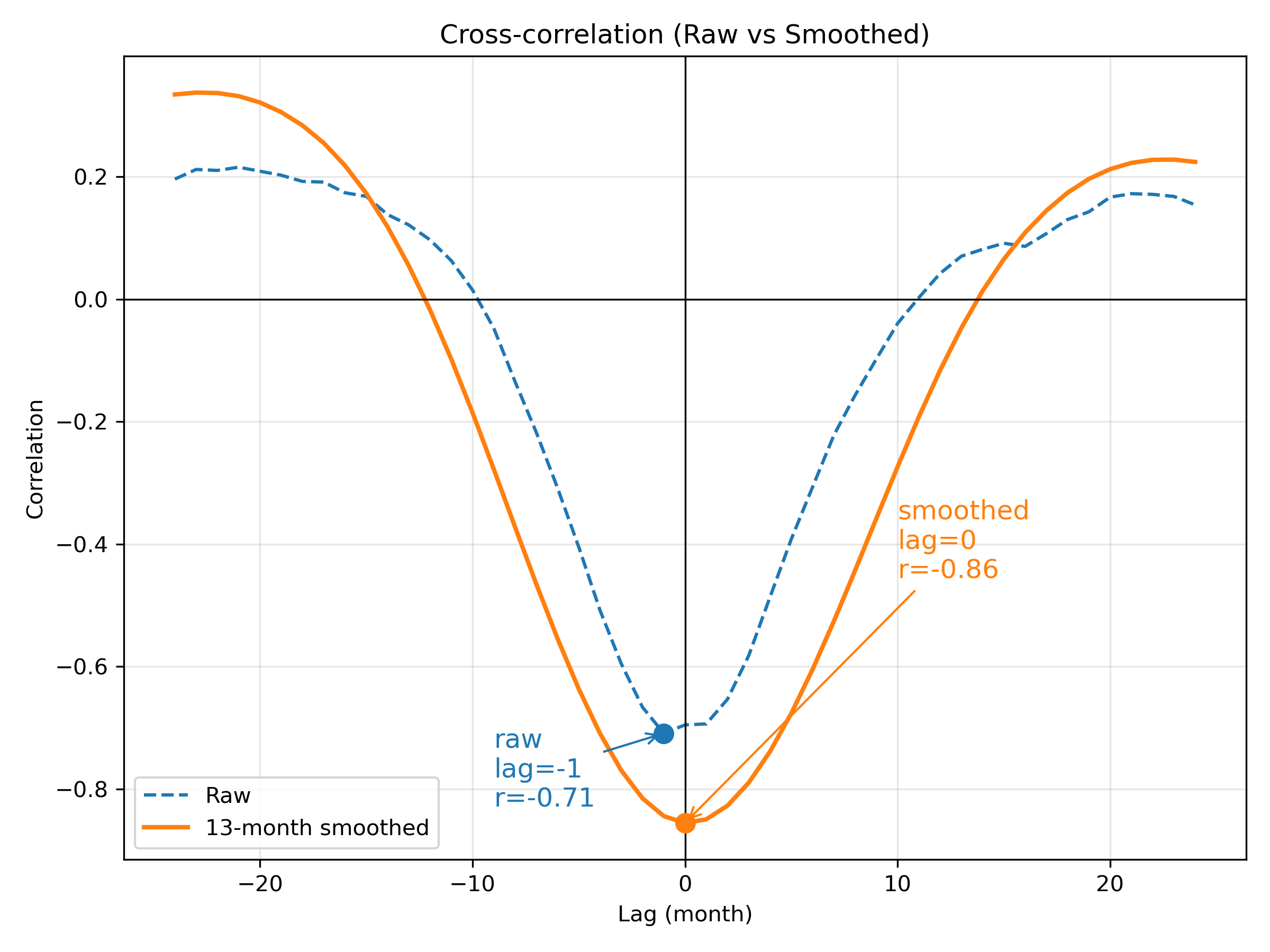
図:フィルタ前後のラグ相関比較。平滑化により関係が明瞭になる
14. まとめ
- SOI と SST anomaly を日付で結合し、共通期間だけを使って解析した
- 相関係数、回帰式、決定係数から、どの海域が ENSO 監視に適しているかを比較した
- NINO3.4 anomaly と SOI の関係は特に強く、負の相関を示すことが多い
- ラグ相関を見ることで、同時性だけでなく時間差のある結びつきも調べられる
- 13か月移動平均を使うと、短周期のばらつきが弱まり、関係の本体が見やすくなる
- 完成コードは 06CompSOIandSST.html のNotebookコードと同じ処理順で、同じ画像ファイル名を保存する
15. 解答の表示
まずは上の穴埋めコードを自分で考えること。確認したい場合だけ、パスワードを入力して解答と完全スクリプトを表示する。
穴埋め解答
sep=r"\s+"
"SOI"
"YEAR"
"MONTH"
sep=r"\s+"
"python"
"YR"
"MON"
"ANOM"
"ANOM.1"
"ANOM.2"
"ANOM.3"
"ANOM"
"ANOM.1"
"ANOM.2"
"ANOM.3"
"DATE"
"inner"
"DATE"
"DATE"
float
float
mask
mask
0, 1
1
2
2
"NINO1+2_ANOM", "NINO3_ANOM", "NINO4_ANOM", "NINO3.4_ANOM"
"SOI"
abs
False
"NINO3.4_ANOM"
"SOI"
0.5
"nino34_soi.png"
300
True
np.nan
2
"NINO3.4_ANOM"
"SOI"
24
imin_raw
imin_raw
"NINO3.4_ANOM", 13
"SOI", 13
24
"sst_soi_lagcor.png"
300完全スクリプト
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# =========================================================
# 1. データ読み込み
# =========================================================
soi_df = pd.read_csv("SOI_timeseries_updated.txt", sep=r"\s+")
soi_df = soi_df.dropna(subset=["SOI"]).reset_index(drop=True)
soi_df["DATE"] = pd.to_datetime(dict(
year=soi_df["YEAR"].astype(int),
month=soi_df["MONTH"].astype(int),
day=1
))
sst_df = pd.read_csv("sstoi.indices", sep=r"\s+", engine="python")
print("SST columns:")
print(sst_df.columns)
sst_df["DATE"] = pd.to_datetime(dict(
year=sst_df["YR"].astype(int),
month=sst_df["MON"].astype(int),
day=1
))
# =========================================================
# 2. SST anomaly 列を整理
# このファイルでは anomaly 列が ANOM, ANOM.1, ...
# =========================================================
sst_use = sst_df[[
"DATE",
"ANOM", # NINO1+2 anomaly
"ANOM.1", # NINO3 anomaly
"ANOM.2", # NINO4 anomaly
"ANOM.3" # NINO3.4 anomaly
]].copy()
sst_use = sst_use.rename(columns={
"ANOM": "NINO1+2_ANOM",
"ANOM.1": "NINO3_ANOM",
"ANOM.2": "NINO4_ANOM",
"ANOM.3": "NINO3.4_ANOM"
})
# =========================================================
# 3. 共通期間で結合
# SOIが2025年3月までなので、共通部分だけを使う
# =========================================================
df = pd.merge(soi_df, sst_use, on="DATE", how="inner")
print("\n共通期間")
print("start:", df["DATE"].min())
print("end :", df["DATE"].max())
print("N :", len(df))
# =========================================================
# 4. 相関・回帰・決定係数を計算する関数
# =========================================================
def calc_stats(x, y):
x = np.asarray(x, dtype=float)
y = np.asarray(y, dtype=float)
mask = np.isfinite(x) & np.isfinite(y)
x = x[mask]
y = y[mask]
# 相関係数
# np.corrcoef(x, y) は 2×2 の相関係数行列を返す
corr_matrix = np.corrcoef(x, y)
r = corr_matrix[0, 1]
# 回帰式 y = a x + b
a, b = np.polyfit(x, y, 1)
# 決定係数
y_pred = a * x + b
ss_res = np.sum((y - y_pred) ** 2)
ss_tot = np.sum((y - np.mean(y)) ** 2)
r2 = 1 - ss_res / ss_tot
return r, a, b, r2, x, y, y_pred
# =========================================================
# 5. 各海域で相関・回帰・決定係数
# =========================================================
regions = ["NINO1+2_ANOM", "NINO3_ANOM", "NINO4_ANOM", "NINO3.4_ANOM"]
results = []
for region in regions:
r, a, b, r2, x_valid, y_valid, y_pred = calc_stats(df[region], df["SOI"])
results.append({
"Region": region,
"Correlation_r": r,
"Slope_a": a,
"Intercept_b": b,
"R2": r2
})
result_df = pd.DataFrame(results)
print("\n各海域の結果")
print(result_df)
# 相関係数は正にも負にもなる。
# ここでは「正か負か」ではなく「関係の強さ」を比べたいので、
# 絶対値をとって abs_r という列を作る。
result_df["abs_r"] = result_df["Correlation_r"].abs()
# abs_r が大きい順に並べる。
# これにより、SOI と関係が強い海域が上に来る。
result_df = result_df.sort_values("abs_r", ascending=False).reset_index(drop=True)
print("\n相関の強い順")
print(result_df[["Region", "Correlation_r", "R2"]])
# =========================================================
# 6. NINO3.4 の散布図と回帰直線
# =========================================================
target = "NINO3.4_ANOM"
r, a, b, r2, x_valid, y_valid, y_pred = calc_stats(df[target], df["SOI"])
plt.figure(figsize=(6, 6))
plt.scatter(x_valid, y_valid, alpha=0.5)
xx = np.linspace(np.min(x_valid), np.max(x_valid), 100)
yy = a * xx + b
plt.plot(xx, yy, linewidth=2)
plt.xlabel("NINO3.4 SST anomaly")
plt.ylabel("SOI")
plt.title("NINO3.4 anomaly vs SOI")
plt.grid(True, alpha=0.3)
plt.text(
0.05, 0.95,
f"r = {r:.2f}\nR² = {r2:.2f}\nSOI = {a:.2f} × SST + {b:.2f}",
transform=plt.gca().transAxes,
verticalalignment="top"
)
plt.tight_layout()
plt.savefig("nino34_soi.png", dpi=300)
plt.show()
# =========================================================
# 7. ラグ相関用関数
# =========================================================
def moving_average(x, window):
return pd.Series(x).rolling(window=window, center=True).mean().to_numpy()
def cross_correlation(x, y, max_lag):
"""
x = SST
y = SOI
lag < 0 : SOI が先行
lag > 0 : SST が先行
"""
x = np.asarray(x, dtype=float)
y = np.asarray(y, dtype=float)
# 調べるラグの一覧を作る。
lags = np.arange(-max_lag, max_lag + 1)
# 計算できない場所は欠損値として残すため、np.nan で初期化する。
cc = np.full(len(lags), np.nan)
for i, lag in enumerate(lags):
if lag < 0:
x1 = x[-lag:]
y1 = y[:len(y) + lag]
elif lag > 0:
x1 = x[:len(x) - lag]
y1 = y[lag:]
else:
x1 = x
y1 = y
# x1 と y1 の両方が有限値である場所だけを使う。
mask = np.isfinite(x1) & np.isfinite(y1)
# 有効なペアが3個以上ある場合だけ相関を計算する。
if np.sum(mask) > 2:
cc[i] = np.corrcoef(x1[mask], y1[mask])[0, 1]
return lags, cc
# =========================================================
# 8. ラグ相関(フィルタなし)
# =========================================================
# x は SST anomaly、y は SOI として使う。
x_raw = df["NINO3.4_ANOM"].to_numpy()
y_raw = df["SOI"].to_numpy()
# SST と SOI の両方が有効な月だけを残す。
mask_raw = np.isfinite(x_raw) & np.isfinite(y_raw)
x_raw = x_raw[mask_raw]
y_raw = y_raw[mask_raw]
# 前後24か月までずらしてラグ相関を計算する。
lags_raw, cc_raw = cross_correlation(x_raw, y_raw, max_lag=24)
# 最も強い負相関を探す。
imin_raw = np.nanargmin(cc_raw)
lag_min_raw = lags_raw[imin_raw]
corr_min_raw = cc_raw[imin_raw]
print("\n【フィルタなし】")
print(f"最も強い負相関: lag = {lag_min_raw}, r = {corr_min_raw:.3f}")
# =========================================================
# 9. ラグ相関(13か月移動平均)
# =========================================================
x_smooth = moving_average(df["NINO3.4_ANOM"].to_numpy(), 13)
y_smooth = moving_average(df["SOI"].to_numpy(), 13)
mask_smooth = np.isfinite(x_smooth) & np.isfinite(y_smooth)
x_smooth = x_smooth[mask_smooth]
y_smooth = y_smooth[mask_smooth]
lags_smooth, cc_smooth = cross_correlation(x_smooth, y_smooth, max_lag=24)
imin_smooth = np.nanargmin(cc_smooth)
lag_min_smooth = lags_smooth[imin_smooth]
corr_min_smooth = cc_smooth[imin_smooth]
print("\n【13か月移動平均後】")
print(f"最も強い負相関: lag = {lag_min_smooth}, r = {corr_min_smooth:.3f}")
# =========================================================
# 10. フィルタなし単独図
# =========================================================
plt.figure(figsize=(7, 5))
plt.plot(lags_raw, cc_raw, linewidth=1.8)
plt.axhline(0, color="k", linewidth=0.8)
plt.axvline(0, color="k", linewidth=0.8)
plt.scatter(lag_min_raw, corr_min_raw, s=70)
plt.text(lag_min_raw, corr_min_raw,
f" lag={lag_min_raw}\n r={corr_min_raw:.2f}",
va="bottom", ha="left")
plt.xlabel("Lag (month)")
plt.ylabel("Correlation")
plt.title("Cross-correlation SST vs SOI (Raw)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =========================================================
# 11. 13か月移動平均後単独図
# =========================================================
plt.figure(figsize=(7, 5))
plt.plot(lags_smooth, cc_smooth, linewidth=1.8)
plt.axhline(0, color="k", linewidth=0.8)
plt.axvline(0, color="k", linewidth=0.8)
plt.scatter(lag_min_smooth, corr_min_smooth, s=70)
plt.text(lag_min_smooth, corr_min_smooth,
f" lag={lag_min_smooth}\n r={corr_min_smooth:.2f}",
va="bottom", ha="left")
plt.xlabel("Lag (month)")
plt.ylabel("Correlation")
plt.title("Cross-correlation (13-month smoothed)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =========================================================
# 12. フィルタなし vs フィルタ後 比較図
# =========================================================
plt.figure(figsize=(8, 6))
# raw
plt.plot(lags_raw, cc_raw, linestyle="--", color="tab:blue", label="Raw")
# smoothed
plt.plot(lags_smooth, cc_smooth, color="tab:orange", linewidth=2, label="13-month smoothed")
plt.axhline(0, color="k", linewidth=0.8)
plt.axvline(0, color="k", linewidth=0.8)
# 最小点
plt.scatter(lag_min_raw, corr_min_raw, color="tab:blue", s=70, zorder=3)
plt.scatter(lag_min_smooth, corr_min_smooth, color="tab:orange", s=70, zorder=3)
# raw の注釈(青)
plt.annotate(
f"raw\nlag={lag_min_raw}\nr={corr_min_raw:.2f}",
xy=(lag_min_raw, corr_min_raw),
xytext=(lag_min_raw - 8, corr_min_raw - 0.12),
arrowprops=dict(arrowstyle="->", color="tab:blue"),
color="tab:blue",
fontsize=12
)
# smoothed の注釈(オレンジ): Lag=10 付近に置く
plt.annotate(
f"smoothed\nlag={lag_min_smooth}\nr={corr_min_smooth:.2f}",
xy=(lag_min_smooth, corr_min_smooth),
xytext=(10, corr_min_smooth + 0.40),
arrowprops=dict(arrowstyle="->", color="tab:orange"),
color="tab:orange",
fontsize=12
)
plt.xlabel("Lag (month)")
plt.ylabel("Correlation")
plt.title("Cross-correlation (Raw vs Smoothed)")
plt.legend(loc="lower left")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("sst_soi_lagcor.png", dpi=300)
plt.show()