1. 背景:全球海面水温は一様に変化するのか
全球平均の海面水温は長期的には上昇傾向を示すが、海のどこでも同じ速さで上がっているわけではない。ある海域では強く上昇し、別の海域では変化が小さかったり、期間によっては低下して見えることもある。
そこで今回は、全球海面水温データを格子点ごとに時間方向へ線形回帰し、海面水温のトレンドを地図として可視化する。また、求めた傾きが統計的に 0 と区別できるかどうかを p 値で判定する。
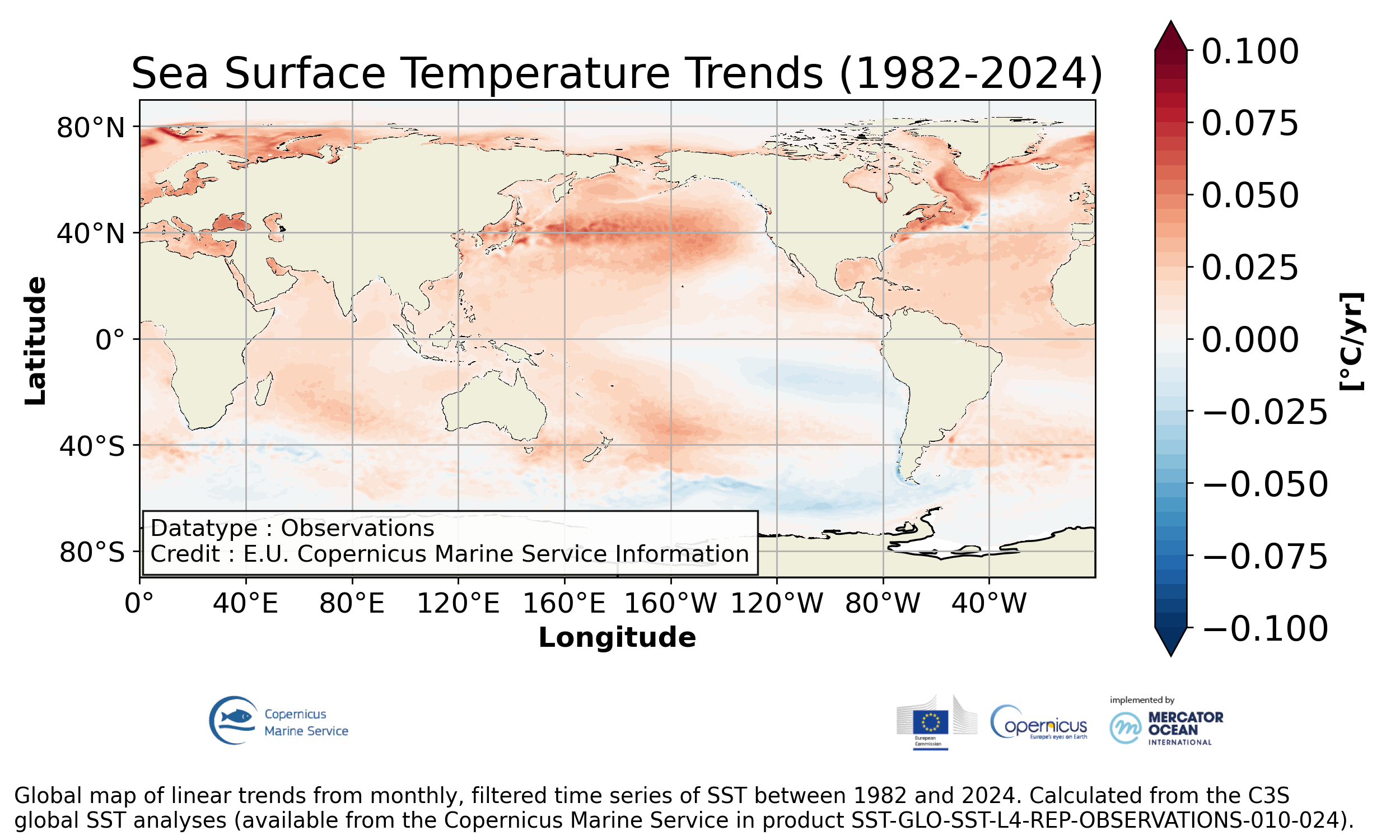
出典: Copernicus Marine Service, GLOBAL_OMI_TEMPSAL_sst_trend
Copernicus 図の Classification
| 項目 | 内容 |
|---|---|
| Full name | Global Ocean Sea Surface Temperature trend map from Observations Reprocessing |
| Product ID | GLOBAL_OMI_TEMPSAL_sst_trend |
| Source | Satellite observations |
| Spatial extent | Global Ocean, Latitude -89.97° to 89.98°, Longitude -179.98° to 179.98° |
| Spatial resolution | 0.05° × 0.05° |
| Temporal extent | Since 1 Jan 1982 |
| Variables | SST trends |
| Indicator family | Sea water temperature |
| Feature type | Grid |
| Format | NetCDF-4 |
| Originating centre | Met Office (UK) |
| Last metadata update | 25 November 2025 |
2. 使用データ
本演習では NOAA Extended Reconstructed SST version 5(ERSSTv5)の月平均海面水温データを使う。ファイルはこのページと同じディレクトリに置いてあるものを使う。
このファイルには sst(time, lat, lon) が格納されている。時間は月単位、緯度は 89 点、経度は 180 点である。単位は degC である。
ERSSTv5 の仕様
| 項目 | 内容 |
|---|---|
| Temporal Coverage | Monthly values for 1854/01 - 現在 |
| Long-term mean | 1981–2010 |
| Spatial Coverage | 全球 2.0° 緯度 × 2.0° 経度格子(89 × 180) |
| Latitude / Longitude | 88.0N - 88.0S, 0.0E - 358.0E |
| Level | Sea Level |
| Update Schedule | Monthly |
| Format | CF metadata standard, NetCDF4 |
| Missing data | -9.96921e+36 |
3. 計算の流れ
- ERSSTv5 の NetCDF ファイルを読み込む
- 解析したい期間を切り出す
- 時間を「年の小数」に変換する
- 各グリッドで y = ax + b の線形回帰を行う
- 傾き a をトレンドとして保存する
- 傾きの p 値を求め、有意な格子点を判定する
- トレンドマップと有意性マップを描く
4. Pythonでよく出る機能の意味
| 書き方 | 意味 |
|---|---|
| xr.open_dataset(...) | NetCDF などの多次元データを読む。 |
| ds["sst"] | 変数 sst を取り出す。 |
| pd.to_datetime(...) | 時間情報を日時型に変換する。 |
| np.isfinite(...) | 有限値かどうかを調べる。NaN を除くときに使う。 |
| np.polyfit(x, y, 1) | 1次式 y = ax + b の傾きと切片を求める。 |
| np.full(shape, np.nan) | 最初から NaN を入れた配列を作る。 |
| stats.t.cdf(...) | t 分布の累積分布関数。p 値の計算に使う。 |
| ax.pcolormesh(...) | 格子状データを色で塗って描く。 |
| ax.scatter(...) | 点を描く。有意な格子点の表示に使う。 |
今回のコードは「データを読む部分」「回帰式を計算する部分」「地図を描く部分」に分けて読むと理解しやすい。
5. データの読み込みと期間の指定
import numpy as np
import xarray as xr
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
import cartopy.crs as ccrs
import cartopy.feature as cfeature
ncfile = "sst.mnmean.nc"
ds = xr.open_dataset(______)
sst = ds["sst"].values.astype(float)
lat = ds["lat"].values
lon = ds["lon"].values
time = pd.to_datetime(ds["time"].values)
sst[sst < -100] = np.nan
start_year = ______
end_year = ______
mask_period = (time.year >= start_year) & (time.year <= end_year)
sst_sub = sst[mask_period, :, :]
time_sub = time[mask_period]ポイント
- xr.open_dataset で NetCDF を読む
- sst[sst < -100] = np.nan で欠損値を NaN にする
- 期間は start_year と end_year を変えるだけで指定できる
このブロックで新しく出るもの
- xarray:多次元配列データを扱うライブラリ
- values:xarray の中身を NumPy 配列として取り出す
- astype(float):計算しやすい型にそろえる
- mask_period:期間選択のための真偽値配列
6. 年の小数への変換
回帰では時間を数値として扱いたいので、年月日ではなく「年の小数」に変換する。
years = time_sub.year + (time_sub.month - ______) / 12.0
years = years.to_numpy(dtype=float)
print(years[:5])
print(years[-5:])ポイント
- 各月の中央付近を表すために 0.5 を使う
- たとえば 1993年1月は 1993.0416... のような値になる
7. 線形回帰と p 値の計算関数
ここでは、各格子点について x = year、y = SST とし、直線 y = ax + b をあてはめる。傾き a が SST トレンドであり、単位は °C/year である。
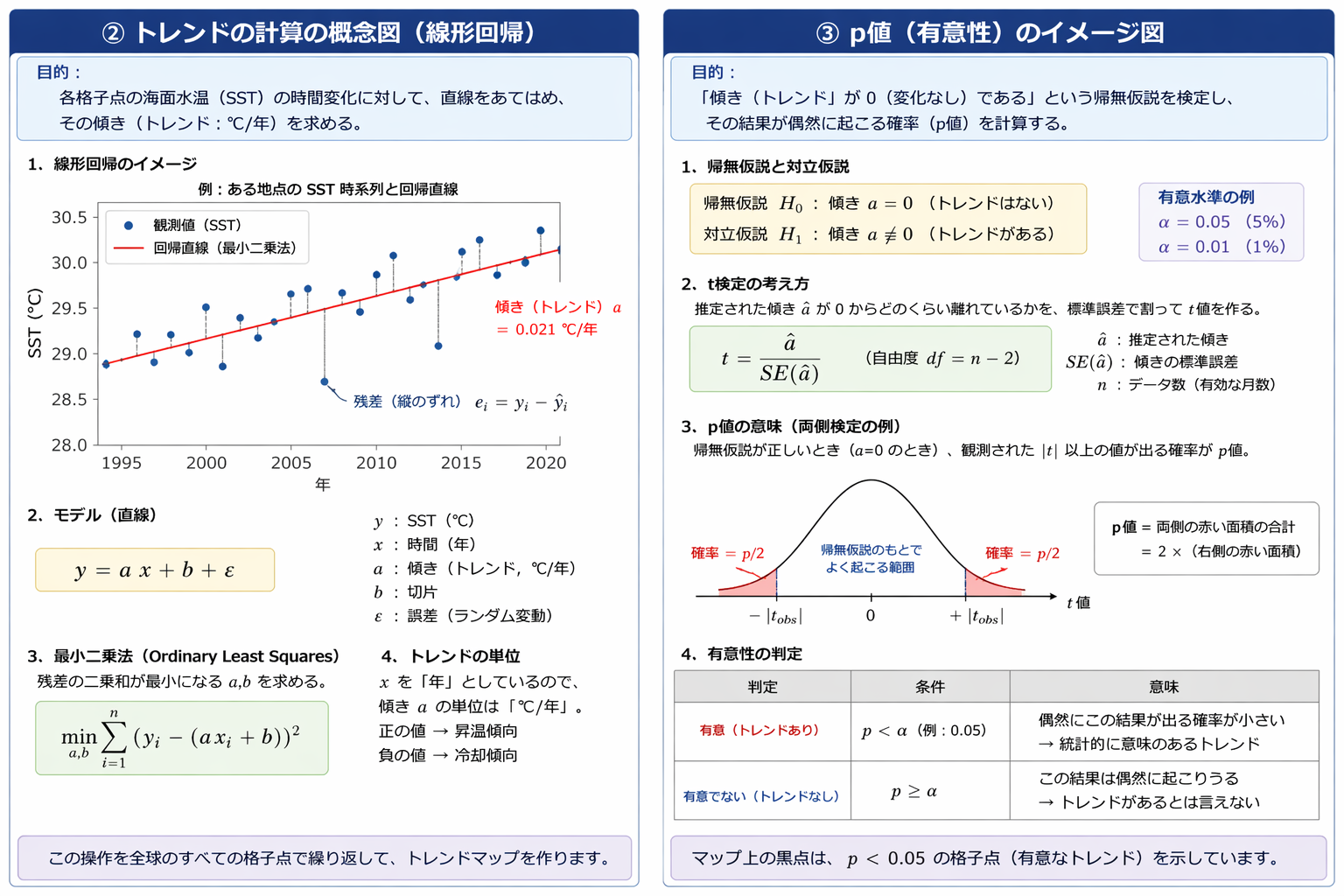
まず、何を検定するのか
この回の検定対象は、相関係数ではなく、回帰直線の傾きである。帰無仮説は次のように置く。
H1: a ≠ 0
a = 0 は「時間が進んでも SST が増減しない」、つまりトレンドがないことを意味する。求めた傾きが 0 から十分離れているかを t 検定で調べる。
最小二乗法で傾き â を求める
観測データを (x_i, y_i) とする。ここでは x_i が年、y_i がその格子点の SST である。回帰直線による予測値を
と書く。観測値と予測値の差を残差という。
最小二乗法では、残差の二乗和
が最小になるように â と b̂ を決める。
傾き â の式が出てくるまで
まず、S を b̂ で微分し、最小値の条件として 0 とおく。
したがって、
両辺を n で割ると、
なので、切片は
となる。つまり、最小二乗法で求めた回帰直線は、平均点 (x̄, ȳ) を通る。
次に、S を â で微分して 0 とおく。
したがって、
ここに b̂ = ȳ − â x̄ を代入する。
括弧の中を整理すると、
ここで、
と置くと、微分条件は
である。一方、b̂ で微分した条件から、残差の和は 0 なので、
も成り立つ。したがって、
ここが、x_i を x_i − x̄ に置き換えてよい理由である。勝手に置き換えているのではなく、ΣA_i = 0 が成り立つため、同じ条件として書ける。
したがって、
これを展開すると、
よって、
この式の読み方
- 分子:x と y が一緒にどれくらい変動しているか
- 分母:x 自体がどれくらい広がっているか
- つまり、傾きは「x が 1 増えたとき、y が平均的にどれくらい変わるか」を表す
傾きの標準誤差 SE(â)
傾き â を求めたら、次にその不確かさを見積もる。まず回帰直線から予測値を作る。
残差の二乗和は、
である。傾きと切片の 2 つをデータから推定しているため、自由度は
となる。残差分散は、
であり、傾きの標準誤差は、
である。点が直線のまわりに大きく散らばっているほど SSres が大きくなり、SE(â) も大きくなる。
ここで切片 b̂ の影響を無視しているわけではない。回帰では、傾き â と切片 b̂ の 2 つを同時にデータから推定している。そのため、残差分散を求めるときの自由度は n − 2 になる。これは、â だけでなく b̂ もデータから決めたことを反映している。
また、最小二乗法で切片も同時に推定すると、回帰直線は必ず平均点 (x̄, ȳ) を通る。つまり、
となる。したがって、切片 b̂ は傾き â と無関係に勝手に決まる量ではない。傾きが決まると、平均点を通るように切片が決まる。
そのため、傾きの不確かさを考えるときには、x_i そのものではなく、平均からどれだけ離れているかを表す x_i − x̄ が重要になる。時間方向にデータが大きく広がっていれば、同じ程度のばらつきがあっても傾きは決めやすい。逆に、観測期間が短く x の広がりが小さいと、少しのばらつきでも傾きの推定は不安定になる。
つまり、SE(â) の式は切片 b̂ を無視した式ではない。切片も同時に推定した効果が、自由度 n − 2 と、平均からのずれ x_i − x̄ という形で入っている。
ここが少しわかりにくいところである。回帰では、â と b̂ を別々に独立して求めているのではなく、2 つのパラメータを同時に推定している。したがって、たしかに â と b̂ の不確かさは無関係ではない。傾きを少し変えると、直線全体の上下位置も変わるため、それを補うように切片も変わる。
しかし、ここで求めたいのは「回帰直線全体の不確かさ」ではなく、そのうち傾き方向の不確かさである。統計的には、推定されたパラメータの不確かさは本来、次のような行列で表される。
この行列の中には、切片 b̂ の分散、傾き â の分散、そして â と b̂ が一緒に動く関係、つまり共分散が入っている。
そのうち、傾き â のばらつきだけを取り出したものが Var(â) であり、その平方根が SE(â) である。つまり、SE(â) は「b̂ を無視した â の不確かさ」ではない。b̂ も同時に推定したうえで、パラメータの不確かさの中から â 方向の成分だけを取り出したものである。
直感的な理解
- 切片 b̂ は、直線全体の上下位置を決める。
- 傾き â は、平均点を中心にして、時間が進むほど上がるのか下がるのかを決める。
- 2 つは完全に独立ではないが、数学的には「上下方向の不確かさ」と「傾き方向の不確かさ」を分けて取り出せる。
したがって、b̂ の影響が混在しているから â の標準誤差と言えない、ということではない。むしろ、混在しているからこそ、回帰係数全体の分散・共分散を考え、その中から傾きに対応する分散成分を取り出す。これが â の標準誤差である。
傾きの t 検定
最後に、傾きが 0 からどれだけ離れているかを、傾きの不確かさで割って t 値を作る。
この式は、傾き â を求める式ではない。傾きはすでに最小二乗法で求めてあり、その傾きが 0 からどれだけはっきり離れているかを調べる式である。
CDF(累積分布関数)とは何か
ここで出てくる Ft は、自由度 df の t 分布の累積分布関数である。英語では cumulative distribution function といい、Python の stats.t.cdf(...) の cdf はこの略である。
累積分布関数は、ある値 x に対して、「その分布に従う値が x 以下になる確率」を返す関数である。つまり、
と書ける。ここで T は、自由度 df の t 分布に従う確率変数である。図で考えると、t 分布の山の左端から x までの面積を表している。
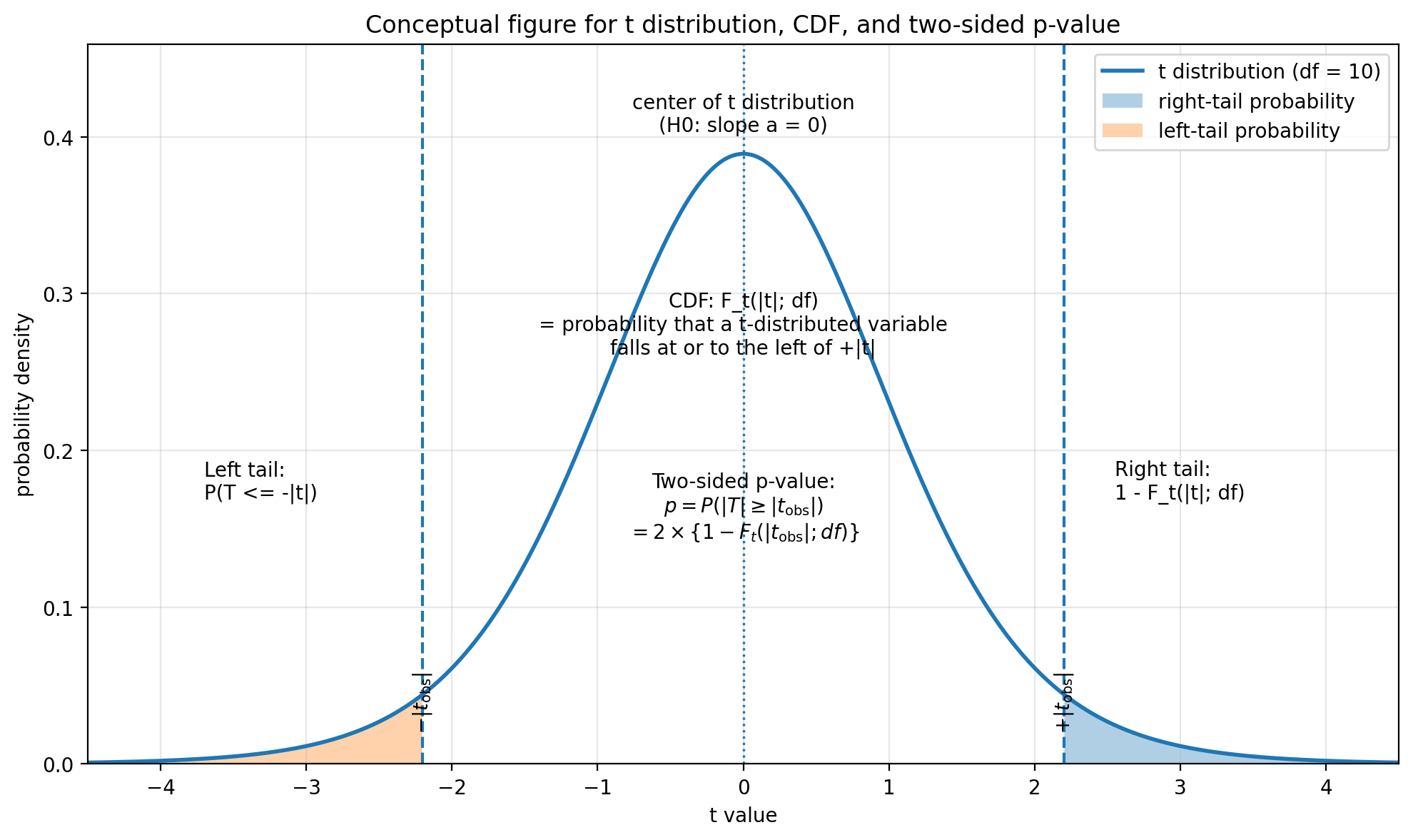
なぜ 1 − CDF を使うのか
t 値を計算したあとに知りたいのは、「今回得られた t 値がどれくらい珍しいか」である。たとえば t = 2.5 だったとする。この値は、傾きが標準誤差 2.5 個分だけ 0 から離れていることを意味する。
このとき p 値で知りたいのは、t 分布において 2.5 よりもさらに外側に出る確率である。しかし、stats.t.cdf(2.5, df=dof) が返すのは「左端から 2.5 までの面積」である。したがって、右側の外側確率は、全体の面積 1 から引いて、
となる。Python では、これが次の部分に対応する。
1 - stats.t.cdf(np.abs(tval), df=dof)なぜ絶対値と 2 倍が出てくるのか
今回の対立仮説は、
である。つまり、傾きが正に大きくても、負に大きくても、どちらも「0 から離れている」と考える。したがって、t = 2.5 も t = −2.5 も、同じように「0 から 2.5 標準誤差分だけ離れている」と扱う。そのため、まず np.abs(tval) で t 値の絶対値をとる。
さらに、1 − Ft(|t|; df) は右側だけの確率である。今回は正方向と負方向の両方を考える両側検定なので、左右の外側確率を足す必要がある。t 分布は 0 を中心に左右対称なので、右側の外側確率を 2 倍すればよい。
これが、Python コードの
pval = 2 * (1 - stats.t.cdf(np.abs(tval), df=dof))に対応している。
自由度 df はなぜ入るのか
t 分布の形は、自由度 df によって変わる。自由度が小さいと、t 分布は裾が厚くなり、大きな t 値が偶然に出る確率が少し高くなる。自由度が大きくなると、t 分布は標準正規分布に近づく。
今回の回帰では、データ数が n 個あっても、そこから傾き â と切片 b̂ の 2 つを推定している。そのため、残差として自由にばらつける情報は 2 つ分減り、
となる。したがって、p 値を計算するときも、自由度 n − 2 の t 分布を使う。
具体例:t = 2.5 のとき
ある格子点で t = 2.5 になったとする。これは、求めた傾きが 0 から標準誤差 2.5 個分だけ離れているという意味である。自由度が十分大きい場合、t 分布で 2.5 より右側に出る確率は小さい。仮に右側確率が 0.008 なら、両側の p 値は、
となる。この場合、p < 0.05 なので、「傾き 0 という仮定では、今回のような傾きはやや珍しい」と判断できる。したがって、その格子点では統計的に有意なトレンドがあると考えやすい。
一方、t = 0.7 のように 0 からあまり離れていない場合、そのような t 値は傾き 0 の世界でも普通に出る。そのため p 値は大きくなり、「この傾きはデータのばらつきの範囲内でも十分起こり得る」と判断される。
この関数で最終的に何がわかるのか
pval は、「本当は傾きが 0 だとしても、今回得られた傾きと同じくらい 0 から離れた傾きが偶然に出る確率」である。したがって、この関数は、各格子点で求めた SST トレンドが、データのばらつきを考慮しても 0 から区別できるかどうかを調べている。
Pythonコードとの対応
def calc_trend_stats(x, y):
x = np.asarray(x, dtype=float)
y = np.asarray(y, dtype=float)
mask = np.isfinite(x) & np.isfinite(y)
x = x[mask]
y = y[mask]
n = len(x)
if n < 3:
return np.nan, np.nan, np.nan, np.nan, np.nan
# 最小二乗法で y = a*x + b を求める
a, b = np.polyfit(x, y, 1)
# 回帰直線による予測値
y_pred = a * x + b
# 残差平方和と全平方和
ss_res = np.sum((y - y_pred) ** 2)
ss_tot = np.sum((y - np.mean(y)) ** 2)
r2 = np.nan if ss_tot == 0 else 1 - ss_res / ss_tot
# x と y の相関係数
r = np.corrcoef(x, y)[0, 1]
# 傾き a の標準誤差と t 検定
# dof は自由度。a と b の2つを推定しているので n - 2
dof = n - 2
# sxx は x の広がり。観測期間が長いほど大きくなる
sxx = np.sum((x - np.mean(x)) ** 2)
# mse は残差分散。回帰直線まわりのばらつき
mse = ss_res / dof
# se_a は傾き a の標準誤差
se_a = np.sqrt(mse / sxx)
# tval は、傾きが 0 から標準誤差何個分離れているか
tval = a / se_a
# pval は両側検定の p 値
# stats.t.cdf は t 分布の累積分布関数(CDF)
pval = 2 * (1 - stats.t.cdf(np.abs(tval), df=dof))
return r, a, b, r2, pvalポイント
- a:傾き。単位は °C/year
- b:切片
- r2:決定係数
- pval:傾きが 0 かどうかを検定したときの p 値
07 では相関係数 r の検定を行った。09 では傾き a の検定を行う。
どちらも t 分布を使うが、「何を 0 と比べているか」が違う。
8. 各格子点でのトレンド計算
nlat = len(lat)
nlon = len(lon)
trend = np.full((nlat, nlon), np.nan)
pval = np.full((nlat, nlon), np.nan)
rmap = np.full((nlat, nlon), np.nan)
r2map = np.full((nlat, nlon), np.nan)
min_count = ______
for i in range(nlat):
for j in range(nlon):
y = sst_sub[:, i, j]
x = years
mask = np.isfinite(y)
if np.sum(mask) < min_count:
continue
r, a, b, r2, p = calc_trend_stats(x[mask], y[mask])
trend[i, j] = ______
pval[i, j] = ______
rmap[i, j] = ______
r2map[i, j] = ______
alpha = 0.05
sig_mask = pval < alphaポイント
- 外側のループは緯度、内側のループは経度
- 各格子で 1 本ずつ回帰直線を求める
- min_count は、有効データが少なすぎる格子を除くための条件である
- trend[i, j] は何を意味するか
- sig_mask[i, j] が True のとき、何が言えるか
9. トレンドマップの描画
fig = plt.figure(figsize=(14, 6))
ax = fig.add_subplot(1, 1, 1,
projection=ccrs.PlateCarree(central_longitude=______))
pcm = ax.pcolormesh(
lon, lat, trend,
transform=ccrs.PlateCarree(),
shading="auto",
cmap="coolwarm",
vmin=-0.10, vmax=0.10
)
ax.add_feature(cfeature.LAND, facecolor="0.85", edgecolor="none", zorder=3)
ax.coastlines(linewidth=0.8, zorder=4)
gl = ax.gridlines(draw_labels=True, linewidth=0.5, color="0.7", alpha=0.8)
gl.top_labels = False
gl.right_labels = False
cbar = fig.colorbar(pcm, ax=ax, pad=0.02, shrink=0.9)
cbar.set_label("Trend (°C/year)")
ax.set_title(f"Global SST Trend (ERSSTv5, {start_year}-{end_year})")
fig.tight_layout()
fig.canvas.draw()
fig.savefig("sst_trend.png", dpi=300, bbox_inches="tight", facecolor="white")
plt.show()ポイント
- central_longitude=180 にすると太平洋が中央にくる
- coolwarm では、暖色が正のトレンド、寒色が負のトレンドを表す
- Cartopy を使うときは、保存前に fig.canvas.draw() を入れると安全である
10. p 値と有意マスクの表示
有意な格子点だけを黒点で重ねて表示する。
yy, xx = np.where(sig_mask)
ax.scatter(
lon[xx], lat[yy],
s=2, c="k", marker="o",
transform=ccrs.PlateCarree(),
zorder=5, alpha=_____
)ポイント
- np.where(sig_mask) は True の場所の添字を返す
- 黒点は「p 値が十分小さい格子点」を表す
- ただし、p 値が小さいことと、物理的に重要であることは同じではない
11. p 値とは何か
今回の検定では、各格子点について次の帰無仮説を考えている。
つまり、「その格子点では長期トレンドがない」と仮定する。この仮定のもとで、実際に得られた傾きと同じくらい、またはそれ以上に 0 から離れた傾きが偶然に出る確率が p 値である。
| 量 | 見ている内容 |
|---|---|
| 傾き a | 何 ℃/年で増減しているか。変化量の大きさ。 |
| 標準誤差 SE(a) | 傾きの不確かさ。点が直線から散らばるほど大きくなる。 |
| t 値 | 傾きが、その不確かさの何倍だけ 0 から離れているか。 |
| p 値 | 傾き 0 という仮定のもとで、今回のような t 値が偶然に出る確率。 |
- p 値が小さい:傾き 0 では説明しにくい。トレンドがあると考えやすい。
- p 値が大きい:傾き 0 でも十分あり得る。トレンドがあるとは言いにくい。
たとえば alpha = 0.05 としたとき、p < 0.05 なら「5%水準で有意」と呼ぶことが多い。
p 値は「トレンドが存在する確率」ではない。また、「p 値が小さいほど変化量が大きい」という意味でもない。
変化量の大きさは 傾き a を見て判断し、統計的に 0 と区別できるかは p 値 を見て判断する。
12. 議論:SST変動は何で説明できるか
ここまでで、各格子点における海面水温(SST)の長期トレンドを求め、 全球平均が上昇していても、その増減の大きさや有意性は空間的に一様ではないことを確認した。 では、この空間分布の違いは何によって説明できるのだろうか。
なぜ、ある海域では SST が大きく変化し、別の海域ではあまり変化しないのか。
短期変動としての ENSO
前回の ENSO コンポジット解析では、El Niño と La Niña のときに 海面水温の分布がどのように変わるかを調べた。 これは、SST の年々変動、つまり比較的短い時間スケールの変動を見ている。
たとえば赤道太平洋では ENSO の影響が強く、ある年には暖かく、 別の年には冷たくなる。このような場所では、SST の分布を理解するうえで ENSO が重要な説明要因になる。
長期変化としてのトレンド
一方、このページで見ているトレンドは、数十年スケールで SST がどの方向に変化してきたかを表している。 これは、温暖化や海洋循環の長期変化など、 長い時間スケールの変動を反映している可能性がある。
したがって、トレンドマップは「この海域では長い目で見ると暖まりやすいのか、 それともあまり変化していないのか」を示している。
ENSOだけで説明できるか
ENSO コンポジットで大きな差が見られる海域では、 年々変動のかなりの部分を ENSO が説明していると考えられる。 しかし、ENSO の影響が弱い海域でも長期トレンドが強く現れることがある。 その場合、SST の変化は ENSO だけでは説明できない。
トレンドだけで説明できるか
逆に、長期トレンドが見られても、年ごとのばらつきが非常に大きい海域では、 実際の SST 変動をトレンドだけで説明することは難しい。 たとえば ENSO のような大きな年々変動が重なると、 長期的には上昇傾向でも、ある年には一時的に低温になることがある。
ENSO は主に短期(年々)変動を説明し、 トレンドは主に長期変化を説明する。
つまり、海面水温の空間分布や時間変動を理解するには、 どちらか一方だけでなく、両方を合わせて考える必要がある。
この回で得たい理解
- ENSO は SST の年々変動を説明する重要な要因である
- トレンドは SST の長期変化を説明する重要な要因である
- 海域によって、どちらが効いているかは異なる
- 一つの要因だけでは、全球の SST 分布を説明できない
- ENSO コンポジットで差が大きかった海域は、トレンドマップではどうなっているか。
- トレンドが大きいのに、ENSO の影響が強くなさそうな海域はどこか。
- ENSO とトレンドのどちらでも説明しきれない海域はありそうか。
このように、SST の変動を理解するには、 短期変動(ENSO)と長期変化(トレンド)を分けて考えることが重要である。 今後はさらに、海面高度や流れの情報も使いながら、 「なぜその場所で変化が起きるのか」を物理的に考えていく。
13. まとめ
- ERSSTv5 の月平均データを NetCDF から読み込んだ
- 時間を年の小数に変換し、各格子点で時間方向の線形回帰を行った
- 傾き a を SST トレンドとして地図に表した
- p 値を計算し、統計的に有意な格子点を重ね描きした
- 全球平均が上昇していても、空間分布は一様ではないことを確認した
14. 解答の表示
まずは上の穴埋めコードを自分で考えること。確認したい場合だけ、パスワードを入力して解答と完全スクリプトを表示する。
穴埋め解答
ncfile
1993
2021
0.5
30
a
p
r
r2
180
0.6完全スクリプト
import numpy as np
import xarray as xr
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
import cartopy.crs as ccrs
import cartopy.feature as cfeature
ncfile = "sst.mnmean.nc"
ds = xr.open_dataset(ncfile)
sst = ds["sst"].values.astype(float)
lat = ds["lat"].values
lon = ds["lon"].values
time = pd.to_datetime(ds["time"].values)
sst[sst < -100] = np.nan
start_year = 1993
end_year = 2021
mask_period = (time.year >= start_year) & (time.year <= end_year)
sst_sub = sst[mask_period, :, :]
time_sub = time[mask_period]
years = time_sub.year + (time_sub.month - 0.5) / 12.0
years = years.to_numpy(dtype=float)
def calc_trend_stats(x, y):
x = np.asarray(x, dtype=float)
y = np.asarray(y, dtype=float)
mask = np.isfinite(x) & np.isfinite(y)
x = x[mask]
y = y[mask]
n = len(x)
if n < 3:
return np.nan, np.nan, np.nan, np.nan, np.nan
a, b = np.polyfit(x, y, 1)
y_pred = a * x + b
ss_res = np.sum((y - y_pred) ** 2)
ss_tot = np.sum((y - np.mean(y)) ** 2)
r2 = np.nan if ss_tot == 0 else 1 - ss_res / ss_tot
r = np.corrcoef(x, y)[0, 1]
dof = n - 2
sxx = np.sum((x - np.mean(x)) ** 2)
mse = ss_res / dof
se_a = np.sqrt(mse / sxx)
tval = a / se_a
pval = 2 * (1 - stats.t.cdf(np.abs(tval), df=dof))
return r, a, b, r2, pval
nlat = len(lat)
nlon = len(lon)
trend = np.full((nlat, nlon), np.nan)
pval = np.full((nlat, nlon), np.nan)
rmap = np.full((nlat, nlon), np.nan)
r2map = np.full((nlat, nlon), np.nan)
min_count = 30
for i in range(nlat):
for j in range(nlon):
y = sst_sub[:, i, j]
x = years
mask = np.isfinite(y)
if np.sum(mask) < min_count:
continue
r, a, b, r2, p = calc_trend_stats(x[mask], y[mask])
trend[i, j] = a
pval[i, j] = p
rmap[i, j] = r
r2map[i, j] = r2
alpha = 0.05
sig_mask = pval < alpha
fig = plt.figure(figsize=(14, 6))
ax = fig.add_subplot(1, 1, 1,
projection=ccrs.PlateCarree(central_longitude=180))
pcm = ax.pcolormesh(
lon, lat, trend,
transform=ccrs.PlateCarree(),
shading="auto",
cmap="coolwarm",
vmin=-0.10, vmax=0.10
)
ax.add_feature(cfeature.LAND, facecolor="0.85", edgecolor="none", zorder=3)
ax.coastlines(linewidth=0.8, zorder=4)
gl = ax.gridlines(draw_labels=True, linewidth=0.5, color="0.7", alpha=0.8)
gl.top_labels = False
gl.right_labels = False
cbar = fig.colorbar(pcm, ax=ax, pad=0.02, shrink=0.9)
cbar.set_label("Trend (°C/year)")
yy, xx = np.where(sig_mask)
ax.scatter(
lon[xx], lat[yy],
s=2, c="k", marker="o",
transform=ccrs.PlateCarree(),
zorder=5, alpha=0.6
)
ax.set_title(f"Global SST Trend (ERSSTv5, {start_year}-{end_year})\nblack dots: p < {alpha}")
fig.tight_layout()
fig.canvas.draw()
fig.savefig("sst_trend.png", dpi=300, bbox_inches="tight", facecolor="white")
plt.show()