1. 背景:EOF/PCAは何をしているのか
EOF(Empirical Orthogonal Function)解析は、気象・海洋データでよく使われる方法である。統計学や機械学習では PCA(Principal Component Analysis:主成分分析)と呼ばれる。ここでは、EOF と PCA を同じ数学的操作として扱う。
EOF/PCAがしていることを一言でいうと、データのばらつきが最も大きい方向を探すことである。2次元散布図で考えると、点群が細長く伸びている方向が第1主成分 PC1、PC1 に直交する方向が第2主成分 PC2 になる。
2. 今回使う2次元データ
今回は、Pythonで x と y の2変数からなる疑似データを作る。y は x にある程度比例するように作るため、散布図は斜め方向に細長く広がる。
1つの点 = [x, y] という2つの値を持つサンプルこの点群に EOF/PCA を適用すると、散布図の長い方向が PC1、短い方向が PC2 として求まる。
| 記号 | 意味 |
|---|---|
| x, y | 元の2つの変数 |
| X | 行がサンプル、列が変数のデータ行列 |
| PC1 | データのばらつきが最も大きい方向 |
| PC2 | PC1に直交する第2の方向 |
3. なぜ標準化するのか
EOF/PCAでは、分散が大きい変数ほど結果に強く効く。もし x と y の単位や大きさが違う場合、単位の大きい変数だけで主成分が決まってしまうことがある。
そこで、各変数について平均を引き、標準偏差で割る。これを標準化という。
標準化後は、各変数の平均が 0、標準偏差が 1 になる。これにより、x と y を同じスケールで比較できる。
4. 共分散行列とは何か
EOF/PCAでは、まずデータのばらつき方を行列として表す。この行列が共分散行列である。2変数の場合、共分散行列は 2 × 2 の行列になる。
| 成分 | 意味 |
|---|---|
| var(x) | x がどれくらいばらつくか |
| var(y) | y がどれくらいばらつくか |
| cov(x,y) | x と y が一緒に増減するかを表す量 |
x と y が一緒に増えたり減ったりする場合、共分散は正になる。散布図が右上がりに伸びる場合である。逆に、一方が増えるともう一方が減る場合は、共分散は負になる。
標準化したデータでは、x と y の分散はおおむね 1 になる。そのため、共分散行列は「2つの変数がどの方向に一緒にばらつくか」を見る行列として扱いやすくなる。
5. 固有値・固有ベクトルとPC軸
共分散行列 C から、固有値と固有ベクトルを求める。ここでは、PC軸またはEOF軸は、共分散行列の固有ベクトルとして求まる。
| 記号 | 意味 |
|---|---|
| C | 共分散行列 |
| a | 固有ベクトル。PCAではPC軸の向き、EOF解析ではEOFパターンに対応する |
| λ | 固有値。その軸方向の分散の大きさを表す |
式 C a = λ a は、「行列 C をベクトル a に作用させても、向きは変わらず、長さだけが λ 倍になる」ことを意味する。このような特別な方向 a が固有ベクトルである。
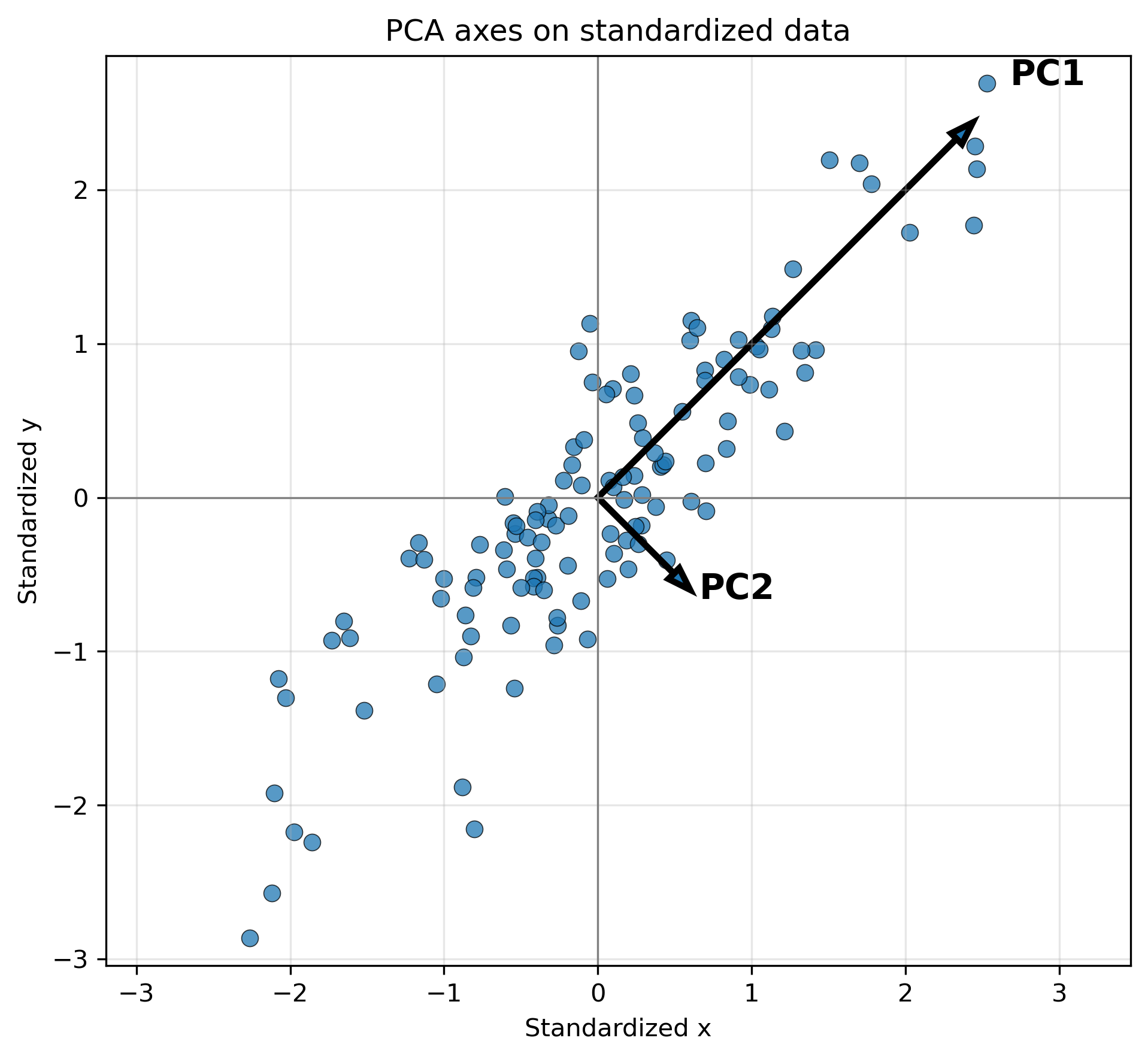
EOF/PCAでは、この固有ベクトルが「データのばらつきが大きい方向」を与える。最も大きな固有値に対応する固有ベクトルが PC1 の方向であり、次に大きな固有値に対応する固有ベクトルが PC2 の方向である。
2変数の場合の式展開
2変数の場合、共分散行列を次のように書く。
固有値 λ は、次の条件を満たす値として求める。
これは λ についての2次方程式である。2次元データでは、この方程式から固有値が2つ出る。その2つの固有値に対応して、固有ベクトルも2本出る。
6. PCスコアと寄与率
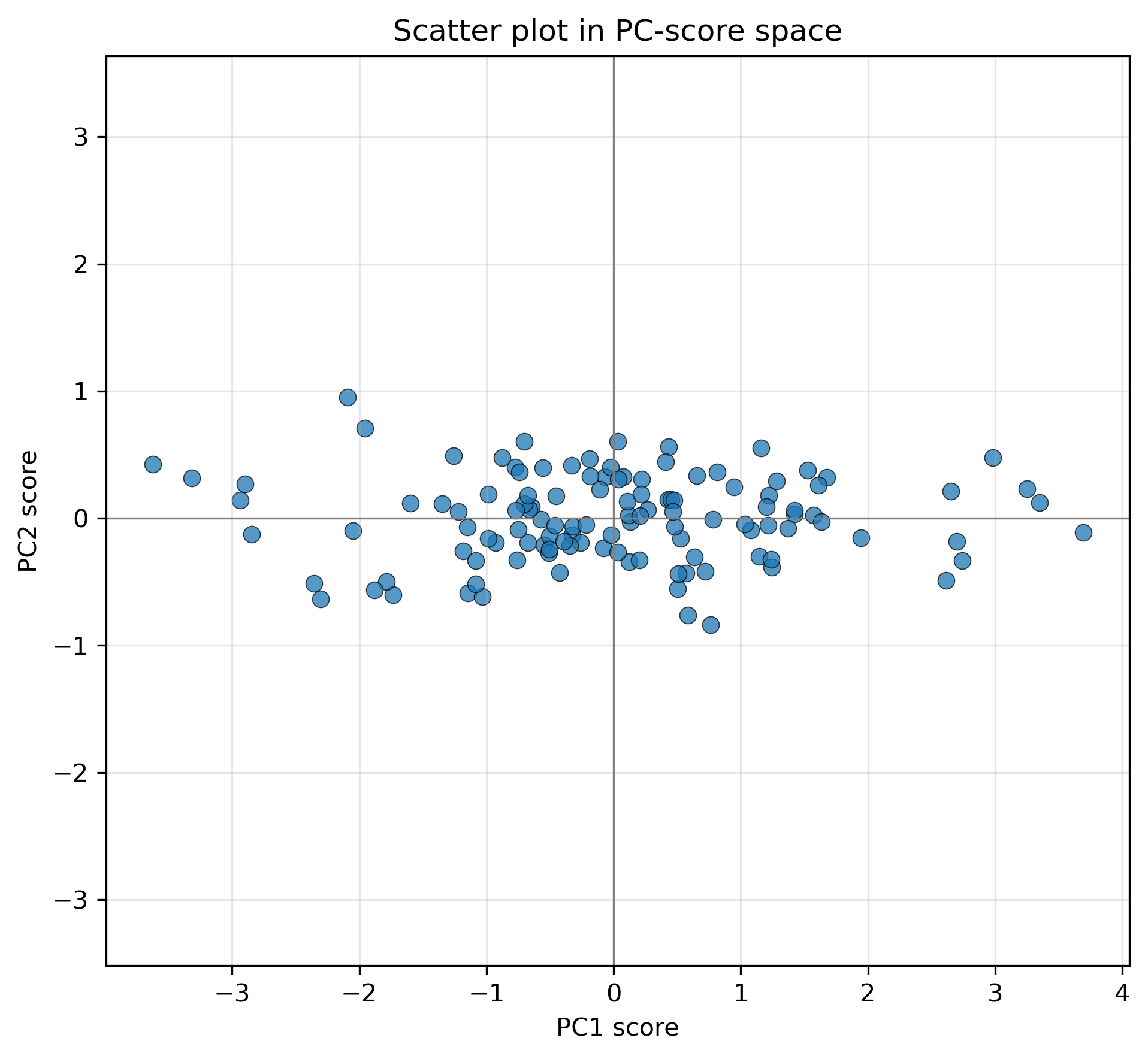
PC軸が求まったら、各データ点をその軸に投影する。この投影された値が PCスコア である。
ここで A は、固有ベクトルを列に並べた行列である。PC1スコアは、各点がPC1方向にどの位置にあるかを表す。PC2スコアは、PC2方向にどの位置にあるかを表す。
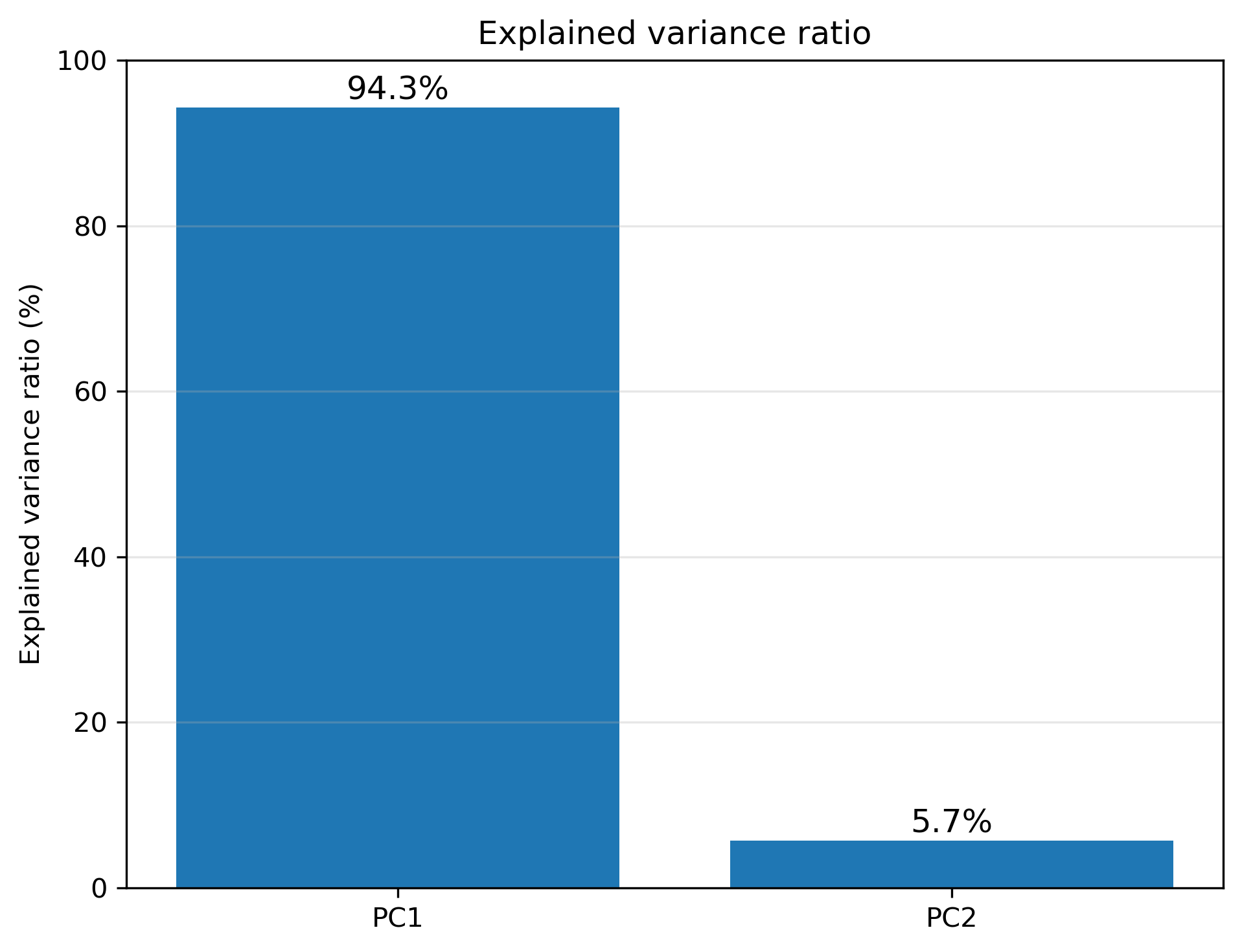
寄与率は、各PCが全体のばらつきをどれだけ説明しているかを表す。
たとえば PC1 の寄与率が 94% なら、データのばらつきのほとんどは PC1 の方向で説明できる。
7. 何モードまで出せるか、どこまで信頼できるか
今回の例では変数が x と y の2つだけなので、出せるモードは最大で2つである。つまり、PC1 と PC2 までで終わる。
| データの形 | 出せるモード数の上限 |
|---|---|
| 今回のように変数が2つ | 最大2モード |
| 変数が m 個 | 最大 m モード |
| サンプル数が N の場合 | 最大でも N−1 モードまで |
一般には、出せるモード数の上限は 変数の数 と サンプル数−1 の小さい方で決まる。
寄与率が近いモードは区別できるのか
EOF解析では、固有値が大きい順にモードを並べる。しかし、隣り合う固有値が非常に近い場合、その2つのモードは統計的に明確に分離できないことがある。
この目安としてよく使われるのが North の rule of thumb である。固有値 λ のサンプリング誤差は、おおまかに次で見積もられる。
ここで N_eff は有効サンプル数である。時系列に自己相関がある場合、単純なデータ数 N より小さくなる。
隣り合う固有値の差がこの誤差幅と同程度以下なら、その2つのモードは入れ替わったり混ざったりしやすい。つまり、モードの解釈には注意が必要である。
8. 作成される図の例
7.1 元データの散布図
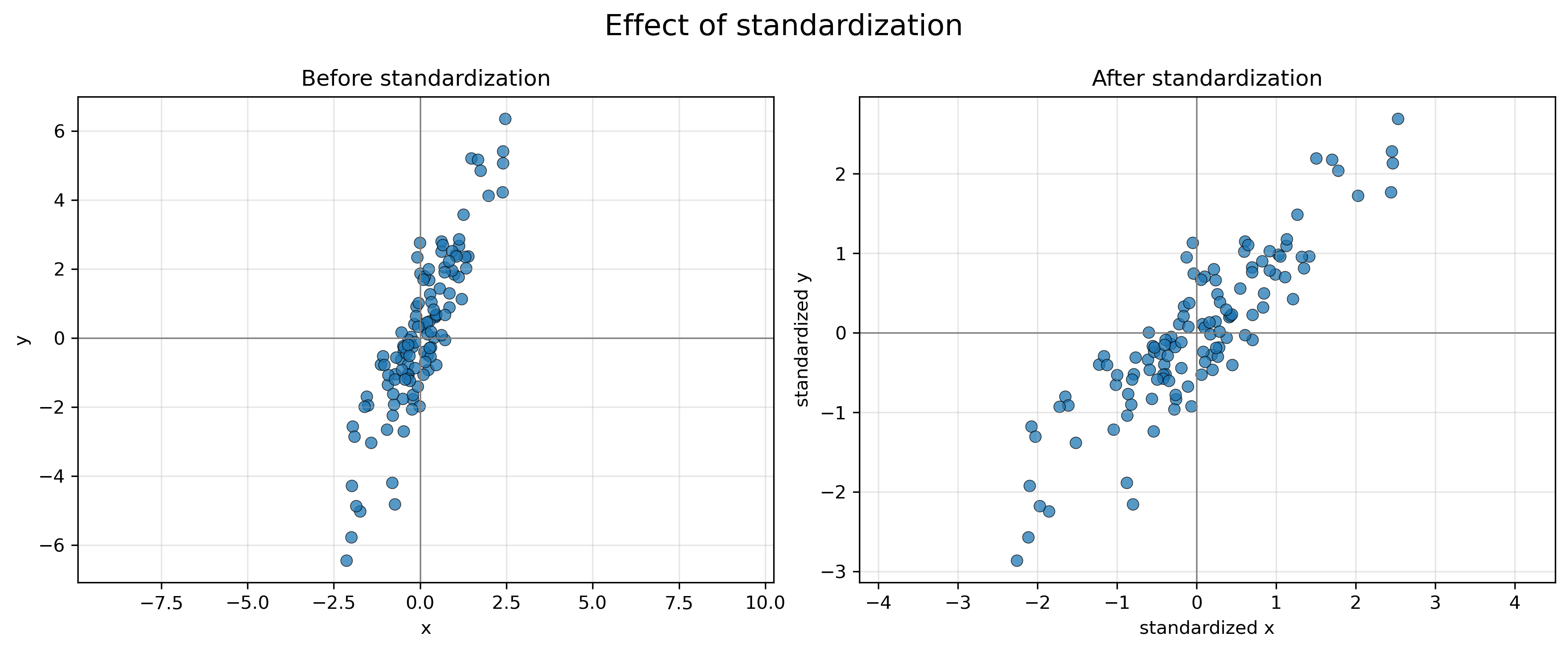
7.2 PCA軸とPCスコア
7.3 寄与率
9. 穴埋めポイント
以下の空欄 ____ を埋めながら、EOF/PCAの計算手順を確認する。
STEP 1:2次元データを作る
np.random.seed(____)
n = ____
x = np.random.normal(loc=0.0, scale=1.0, size=n)
noise = np.random.normal(loc=0.0, scale=0.7, size=n)
y = ____ * x + noise
X = np.column_stack([____, ____])STEP 2:標準化する
X_mean = X.mean(axis=____)
X_std = X.std(axis=____, ddof=1)
X_stdzd = (X - ____) / ____STEP 3:共分散行列を作る
C = np.cov(X_stdzd, rowvar=____)STEP 4:固有値・固有ベクトルを求める
eigvals, eigvecs = np.linalg.eigh(____)
idx = np.argsort(eigvals)[____]
eigvals = eigvals[idx]
eigvecs = eigvecs[:, idx]STEP 5:PCスコアと寄与率を計算する
scores = X_stdzd @ ____
explained_ratio = eigvals / eigvals.____()10. 穴埋め版スクリプト
以下を Jupyter Lab のセルにそのまま貼り付け、____ を埋めてから実行する。今回は図の保存は行わず、Jupyter上に表示するだけである。
# ============================================================
# 15. EOF初級編:2次元データで理解するPCA/EOF
# ============================================================
#
# このスクリプトで行うこと
# 1. 2変数 x, y の疑似データを作る
# 2. 標準化する
# 3. 共分散行列を計算する
# 4. 固有値・固有ベクトルを求める
# 5. EOF軸、PCスコア、寄与率を可視化する
#
# 図は保存せず、表示だけ行う。
# ============================================================
import numpy as np
import matplotlib.pyplot as plt
# ============================================================
# 1. 2次元データを作る
# ============================================================
np.random.seed(____) # 例:1
n = ____ # 例:100
x = np.random.normal(loc=0.0, scale=1.0, size=n)
noise = np.random.normal(loc=0.0, scale=0.7, size=n)
y = ____ * x + noise # 例:2.4
# 外れ気味の点を少し加える
x[:8] = x[:8] + np.linspace(-1.5, 2.0, 8)
y[:8] = y[:8] + np.linspace(-3.5, 4.0, 8)
# 行がサンプル、列が変数のデータ行列にする
X = np.column_stack([____, ____]) # x, y
print("Data shape:", X.shape)
print("First 5 rows:")
print(X[:5])
# ============================================================
# 2. 元データの散布図
# ============================================================
plt.figure(figsize=(7, 6))
plt.scatter(x, y, s=70, alpha=0.75, edgecolor="k", linewidth=0.5)
plt.axhline(0, color="0.5", linewidth=1)
plt.axvline(0, color="0.5", linewidth=1)
plt.grid(True, alpha=0.3)
plt.xlabel("Variable 1: x")
plt.ylabel("Variable 2: y")
plt.title("Two-dimensional scatter plot")
plt.xlim(-7.5, 7.5)
plt.ylim(-7.0, 7.0)
plt.show()
# ============================================================
# 3. 標準化
# ============================================================
#
# 各変数から平均を引き、標準偏差で割る。
# 標準化後は、各変数の平均が0、標準偏差が1になる。
# ============================================================
X_mean = X.mean(axis=____) # 0
X_std = X.std(axis=____, ddof=1) # 0
X_stdzd = (X - ____) / ____ # X_mean, X_std
x_std = X_stdzd[:, 0]
y_std = X_stdzd[:, 1]
print("Mean before standardization:", X_mean)
print("Std before standardization :", X_std)
print("Mean after standardization :", X_stdzd.mean(axis=0))
print("Std after standardization :", X_stdzd.std(axis=0, ddof=1))
# ============================================================
# 4. 標準化前後の比較図
# ============================================================
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(x, y, s=55, alpha=0.75, edgecolor="k", linewidth=0.5)
axes[0].axhline(0, color="0.5", linewidth=1)
axes[0].axvline(0, color="0.5", linewidth=1)
axes[0].grid(True, alpha=0.3)
axes[0].set_title("Before standardization")
axes[0].set_xlabel("x")
axes[0].set_ylabel("y")
axes[0].set_xlim(-10, 10)
axes[0].set_ylim(-7, 7)
axes[1].scatter(x_std, y_std, s=55, alpha=0.75, edgecolor="k", linewidth=0.5)
axes[1].axhline(0, color="0.5", linewidth=1)
axes[1].axvline(0, color="0.5", linewidth=1)
axes[1].grid(True, alpha=0.3)
axes[1].set_title("After standardization")
axes[1].set_xlabel("standardized x")
axes[1].set_ylabel("standardized y")
axes[1].set_xlim(-4.5, 4.5)
axes[1].set_ylim(-3.2, 3.2)
fig.suptitle("Effect of standardization", fontsize=18)
plt.tight_layout()
plt.show()
# ============================================================
# 5. 共分散行列を計算する
# ============================================================
#
# rowvar=False とすることで、列を変数として扱う。
# 今回は列が x と y である。
# ============================================================
C = np.cov(X_stdzd, rowvar=____) # False
print("Covariance matrix:")
print(C)
# ============================================================
# 6. 固有値・固有ベクトルを求める
# ============================================================
#
# 固有ベクトル:PC軸、またはEOF軸の方向
# 固有値:その軸方向の分散の大きさ
# 数学的には C a = lambda a を満たす a と lambda を求める
# ============================================================
eigvals, eigvecs = np.linalg.eigh(____) # C
# 固有値を大きい順に並べ替える
idx = np.argsort(eigvals)[____] # ::-1
eigvals = eigvals[idx]
eigvecs = eigvecs[:, idx]
print("Eigenvalues:")
print(eigvals)
print("Eigenvectors:")
print(eigvecs)
# ============================================================
# 7. 寄与率を計算する
# ============================================================
explained_ratio = eigvals / eigvals.____() # sum
print("Explained variance ratio:")
print(explained_ratio)
print("Explained variance ratio (%):")
print(explained_ratio * 100)
# ============================================================
# 8. 標準化データ上にPCA軸を描く
# ============================================================
pc1 = eigvecs[:, 0]
pc2 = eigvecs[:, 1]
scale1 = 2.5 * np.sqrt(eigvals[0])
scale2 = 2.5 * np.sqrt(eigvals[1])
plt.figure(figsize=(8, 7))
plt.scatter(x_std, y_std, s=70, alpha=0.75, edgecolor="k", linewidth=0.5)
plt.axhline(0, color="0.5", linewidth=1)
plt.axvline(0, color="0.5", linewidth=1)
# PC1軸
plt.arrow(
0, 0,
pc1[0] * scale1,
pc1[1] * scale1,
head_width=0.12,
head_length=0.18,
linewidth=3,
length_includes_head=True,
color="black"
)
# PC2軸
plt.arrow(
0, 0,
pc2[0] * scale2,
pc2[1] * scale2,
head_width=0.12,
head_length=0.18,
linewidth=3,
length_includes_head=True,
color="black"
)
plt.text(pc1[0] * scale1 * 1.05, pc1[1] * scale1 * 1.05, "PC1", fontsize=18, weight="bold")
plt.text(pc2[0] * scale2 * 1.15, pc2[1] * scale2 * 1.15, "PC2", fontsize=18, weight="bold")
plt.grid(True, alpha=0.3)
plt.xlabel("Standardized x")
plt.ylabel("Standardized y")
plt.title("PCA axes on standardized data")
plt.xlim(-3.2, 3.5)
plt.ylim(-3.1, 3.0)
plt.show()
# ============================================================
# 9. PCスコアを計算する
# ============================================================
#
# PCスコアとは、各データ点をEOF軸に射影した値である。
# scores[:,0] が PC1スコア
# scores[:,1] が PC2スコア
# ============================================================
scores = X_stdzd @ ____ # eigvecs
pc1_score = scores[:, 0]
pc2_score = scores[:, 1]
print("PC score shape:", scores.shape)
print("First 5 PC scores:")
print(scores[:5])
# ============================================================
# 10. PCスコア空間の散布図
# ============================================================
plt.figure(figsize=(8, 7))
plt.scatter(pc1_score, pc2_score, s=70, alpha=0.75, edgecolor="k", linewidth=0.5)
plt.axhline(0, color="0.5", linewidth=1)
plt.axvline(0, color="0.5", linewidth=1)
plt.grid(True, alpha=0.3)
plt.xlabel("PC1 score")
plt.ylabel("PC2 score")
plt.title("Scatter plot in PC-score space")
plt.xlim(-4.0, 4.2)
plt.ylim(-3.5, 3.5)
plt.show()
# ============================================================
# 11. 寄与率を棒グラフで表示
# ============================================================
plt.figure(figsize=(8, 6))
labels = ["PC1", "PC2"]
values = explained_ratio * 100
plt.bar(labels, values)
for i, v in enumerate(values):
plt.text(i, v + 1.0, f"{v:.1f}%", ha="center", fontsize=16)
plt.ylim(0, 100)
plt.ylabel("Explained variance ratio (%)")
plt.title("Explained variance ratio")
plt.grid(axis="y", alpha=0.3)
plt.show()
# ============================================================
# 12. 結果のまとめ
# ============================================================
print("============================================================")
print("Summary")
print("============================================================")
print(f"PC1 explained variance ratio: {explained_ratio[0]*100:.1f}%")
print(f"PC2 explained variance ratio: {explained_ratio[1]*100:.1f}%")
print("")
print("PC1 direction vector:", pc1)
print("PC2 direction vector:", pc2)
11. 結果の見方
- 散布図が斜め方向に細長い場合、PC1 はその長軸方向を向く。
- PC2 は PC1 と直交し、残りのばらつきを表す。
- PC1 の寄与率が高い場合、2変数のばらつきの多くは1本の軸で説明できる。
- PCスコアは、各データ点を新しいPC軸に投影した座標である。
- なぜ標準化する必要があるのか。
- PC1の向きは、元の散布図のどの方向に対応しているか。
- PC1の寄与率が高いとは、何を意味しているか。
- PCスコア空間では、元の散布図と何が変わっているか。
- 寄与率が近い2つのモードは、常に別々に解釈してよいか。
- North の rule of thumb では、どのようなときにモード分離が難しいと考えるか。
12. まとめ
- EOF/PCAは、データのばらつきが最大となる方向を求める方法である。
- 標準化により、変数の単位やスケールの違いをそろえることができる。
- 共分散行列の固有ベクトルがPC軸またはEOF軸、固有値がその軸方向の分散を表す。
- PCスコアは、各データ点をEOF軸に射影した値である。
- 寄与率は、各PCが全体のばらつきをどれだけ説明するかを表す。
- 出せるモード数は、変数の数とサンプル数によって制限される。
- 隣り合う固有値が近い場合、North の rule of thumb によりモード分離の信頼性を考える必要がある。