1. 背景:2026年夏までにエルニーニョになるのか
エルニーニョは、熱帯太平洋の海面水温が平年より高くなり、大気循環も変化する現象である。気象・海洋のデータサイエンスでは、エルニーニョを単に「起こった後に説明する」だけでなく、現在までのデータから数か月先を予測することが重要になる。
実際に、2026年春の時点でも、エルニーニョ・ラニーニャの今後に関する情報は気象庁や報道で取り上げられている。まずは、次のような外部情報を確認しておくと、今回の解析の位置づけが分かりやすい。
ただし、このページで行うのは公式予報ではない。公開されているNINO3.4とSOIのデータを使って、統計的にどのような予測ができるのかを自分で確かめることが目的である。
今回の問いは次である。
2. 現在の判定と未来予測の違い
まず大事なのは、現在の判定と未来予測は違う、という点である。
| 考え方 | 見るもの | 例 |
|---|---|---|
| 現在の判定 | 今のNINO3.4が閾値を超えているか | 2026年4月のNINO3.4は +0.47℃。+0.5℃に近いが、単月だけで「発生」とは判定しない。 |
| 未来予測 | 4月までの状態から、その後のJJA/JAS/OND/NDJを予測する | 過去の年で、4月までの状態が似ていた年は、その後どうなったかを学習する。 |
今回のロジスティック回帰では、1982〜2025年の各年について「4月までに分かる情報」と「その後の夏・冬の結果」の関係を学習し、その関係を2026年に適用する。
3. 使用データ:NINO3.4とSOI
今回使う主な指標は2つである。
使用するデータファイル
このページのPythonコードは、HTMLファイルと同じディレクトリに次のファイルを置いて実行する。
- sstoi.indices
NINO1+2, NINO3, NINO4, NINO3.4 の月別SSTと偏差を含むファイル。今回の解析では NINO3.4 の偏差を使う。 - SOI_timeseries_updated2.txt
YEAR, MONTH, SOI, TIME からなる月別SOI時系列。今回の解析では SOI を使う。 - Tahiti.txt / Darwin.txt
SOIを自分で作り直す場合に使う、タヒチとダーウィンの海面気圧データ。
JupyterLabで実行する場合は、これらのデータファイルとノートブックを同じフォルダに置く。
| 指標 | 意味 | エルニーニョとの関係 |
|---|---|---|
| NINO3.4 | 赤道太平洋中央部の海面水温偏差 | 値が高いほど、海洋側はエルニーニョ方向 |
| SOI | タヒチとダーウィンの海面気圧差から作る大気指標 | 負のSOIは、一般にエルニーニョ方向の大気シグナル |
NINO3.4は海洋側、SOIは大気側の情報である。この2つを同時に見ることで、海洋だけでなく大気もエルニーニョ方向に変化しているかを確認できる。
4. 4月までにわかる特徴量を作る
未来予測では、未来の値を説明変数に入れてはいけない。今回は、各年について1月〜4月までに分かる情報だけを使う。
| 特徴量 | 値 | 読み方 |
|---|---|---|
| NINO3.4(4月) | 0.470 | +0.5℃にかなり近い。現在の海面水温がエルニーニョ側へ近づいている。 |
| NINO3.4(1月→4月の変化) | 1.010 | 1月から4月に+1℃以上上昇。急速に暖かくなっている。 |
| SOI(4月) | -0.638 | 負のSOIはエルニーニョ方向の大気シグナル。 |
| SOI(1月→4月の変化) | -1.737 | SOIが大きく低下。大気側もエルニーニョ方向へ変化している。 |
5. 何を予測するのか:発生予測と強度予測
予測では、まず何を当てたいのかを明確にする必要がある。今回は、次の6種類の目的変数を作った。
| 予測対象 | 意味 | 種類 |
|---|---|---|
| JJA ≥ +0.5 | 6〜8月平均のNINO3.4が+0.5℃以上 | 夏の発生予測 |
| JAS ≥ +0.5 | 7〜9月平均のNINO3.4が+0.5℃以上 | 夏〜初秋の発生予測 |
| OND ≥ +1.5 | 10〜12月平均のNINO3.4が+1.5℃以上 | 年末の強度予測 |
| OND ≥ +2.0 | 10〜12月平均のNINO3.4が+2.0℃以上 | 年末のvery strong予測 |
| NDJ ≥ +1.5 | 11〜1月平均のNINO3.4が+1.5℃以上 | 冬の強度予測 |
| NDJ ≥ +2.0 | 11〜1月平均のNINO3.4が+2.0℃以上 | 冬のvery strong予測 |
6. ロジスティック回帰とは何か
ロジスティック回帰は、結果が「起こる / 起こらない」のような2択のときに使う方法である。今回なら、例えば「JJAにNINO3.4が+0.5℃以上になるか」を0または1で表す。
ここで p が、イベントが起こる確率である。p=0.84 なら、そのモデルは「起こる確率を84%と推定した」という意味になる。
ただし、これは公式予報の確率ではない。今回のモデルは、NINO3.4とSOIだけを使った簡易的な統計モデルである。
重回帰に似ているところ
ロジスティック回帰は、説明変数を足し合わせて z を作る点では重回帰に似ている。そのため、説明変数どうしが似た情報を持っていると、重回帰と同じように多重共線性が問題になる。
7. 主モデルをどう選ぶか
最初は、4月値、2〜4月平均、1月から4月への変化量をすべて入れた6変数モデルを試した。しかし、2〜4月平均は4月値を含むため、説明変数どうしが強く似てしまう。
そこで、今回の主モデルは次の4変数にした。
| 説明変数 | 意味 |
|---|---|
| NINO34_Apr | 4月時点で海洋側がどれくらいエルニーニョ寄りか |
| NINO34_JanApr_change | 1月から4月に海洋側がどれくらいエルニーニョ方向へ変化したか |
| SOI_Apr | 4月時点の大気側の状態 |
| SOI_JanApr_change | 1月から4月に大気側がどれくらいエルニーニョ方向へ変化したか |
8. 多重共線性とVIF
説明変数どうしが強く相関している状態を多重共線性という。多重共線性が強いと、予測自体はできても、係数の解釈が不安定になる。
例えば、NINO34_Apr と NINO34_FMA を同時に入れると、どちらも「春にNINO3.4が高い」という似た情報を持つ。すると、モデルはどちらに重みを置けばよいか分かりにくくなる。
8.1 相関行列で確認する
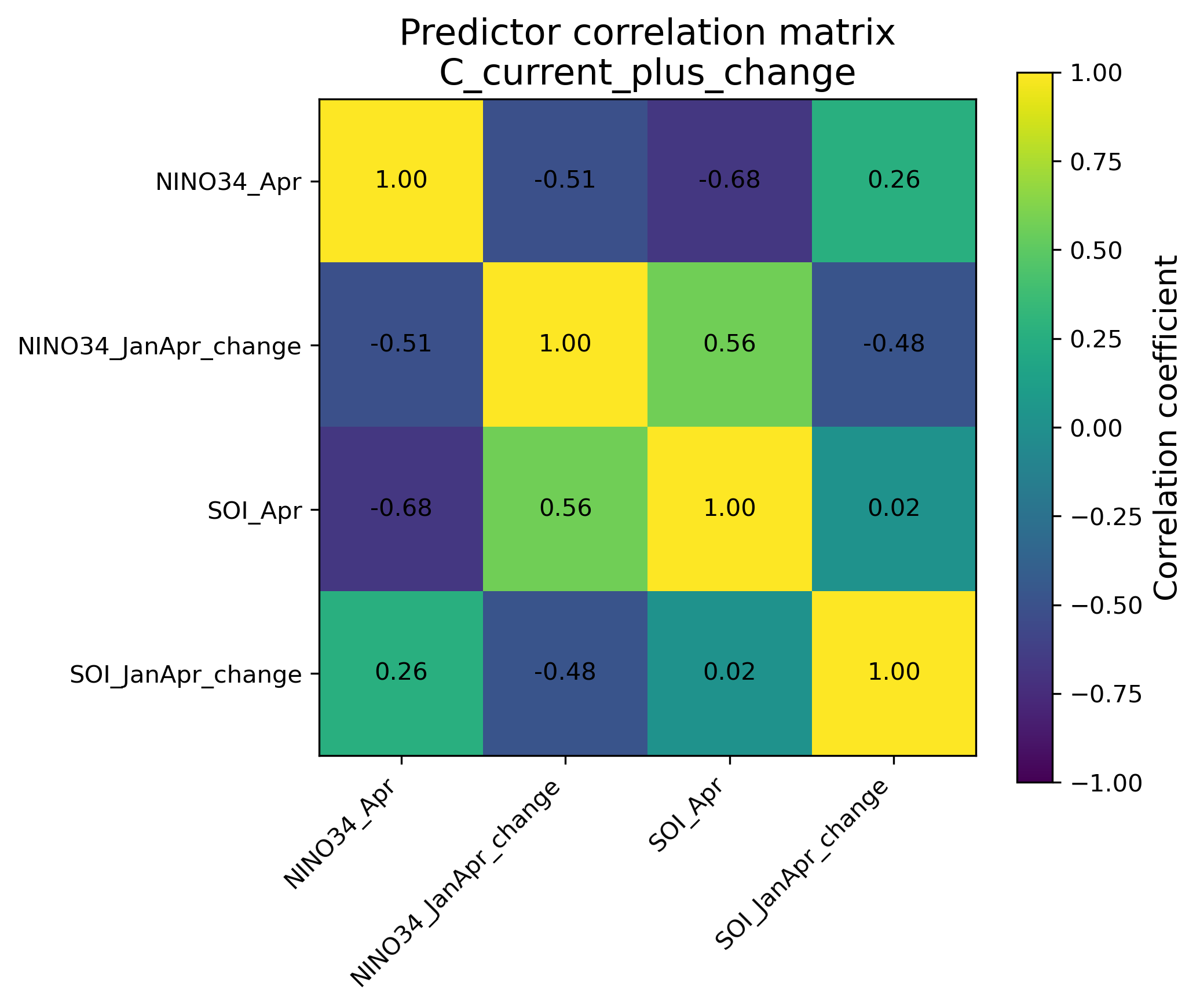
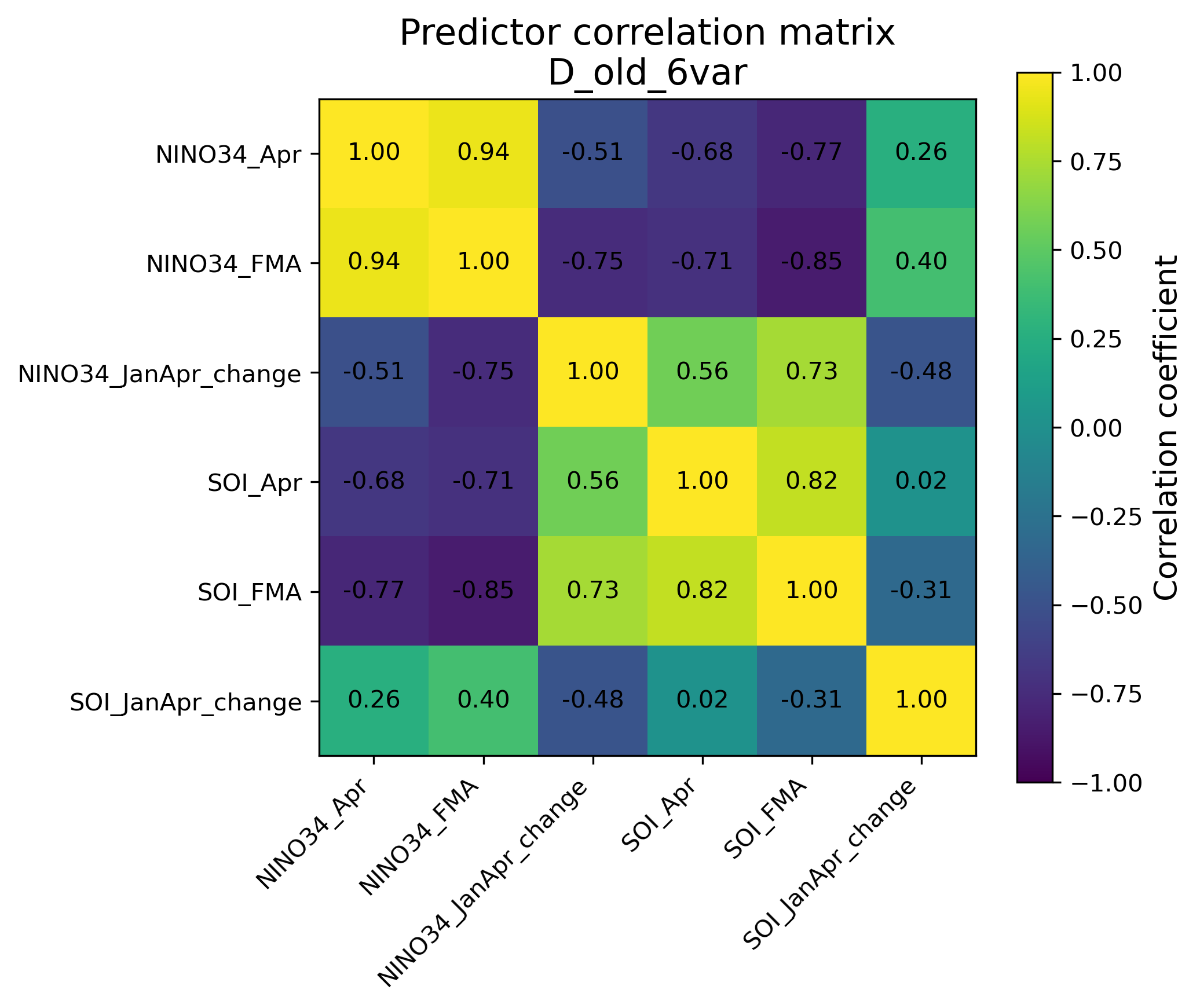
旧6変数モデルでは、NINO34_Apr と NINO34_FMA の相関が0.94、SOI_Apr と SOI_FMA の相関が0.82である。これは、かなり似た情報を重複して使っていることを意味する。
8.2 VIFとは何か
相関行列は2つの変数どうしの関係を見る。一方で、VIFは「ある説明変数が、他の説明変数全体によってどれくらい説明されてしまうか」を見る。
ここで R² は、ある説明変数を他の説明変数で回帰したときの決定係数である。VIFが大きいほど、その説明変数は他の説明変数と似た情報を持つ。
| VIF | 目安 |
|---|---|
| 1〜2 | 問題小さい 他の説明変数とはあまり重複しない |
| 2〜5 | やや注意 相関はあるが、多くの場合は許容範囲 |
| 5〜10 | 注意 多重共線性を疑う |
| 10以上 | 深刻 係数の解釈はかなり不安定 |
8.3 主モデル C のVIF
| 説明変数 | VIF | 判断 |
|---|---|---|
| NINO34_Apr | 2.14 | やや注意 ただし許容範囲 |
| NINO34_JanApr_change | 2.27 | やや注意 ただし許容範囲 |
| SOI_Apr | 2.75 | やや注意 ただし許容範囲 |
| SOI_JanApr_change | 1.72 | 問題小さい |
8.4 旧6変数モデル D のVIF
| 説明変数 | VIF | 判断 |
|---|---|---|
| NINO34_Apr | 31.27 | 深刻 |
| NINO34_FMA | 51.41 | 非常に深刻 |
| NINO34_JanApr_change | 8.10 | 注意 |
| SOI_Apr | 4.38 | やや注意 |
| SOI_FMA | 6.22 | 注意 |
| SOI_JanApr_change | 2.00 | 問題小さい |
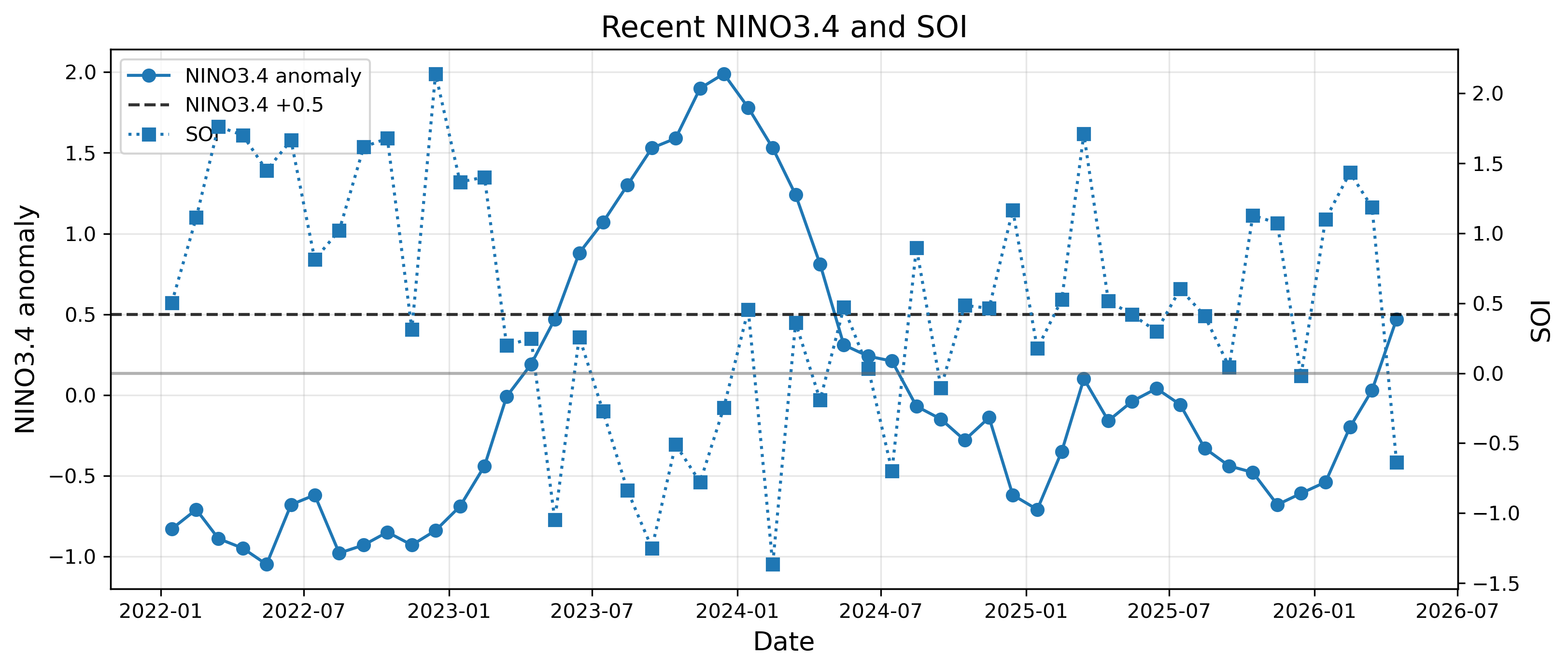
9. 結果1:2026年4月までの状態
まず、2022年以降のNINO3.4とSOIを見る。2023年には強いエルニーニョがあり、その後いったんNINO3.4は下がった。しかし2026年に入ってから、NINO3.4は急速に上昇している。
10. 結果2:予測確率
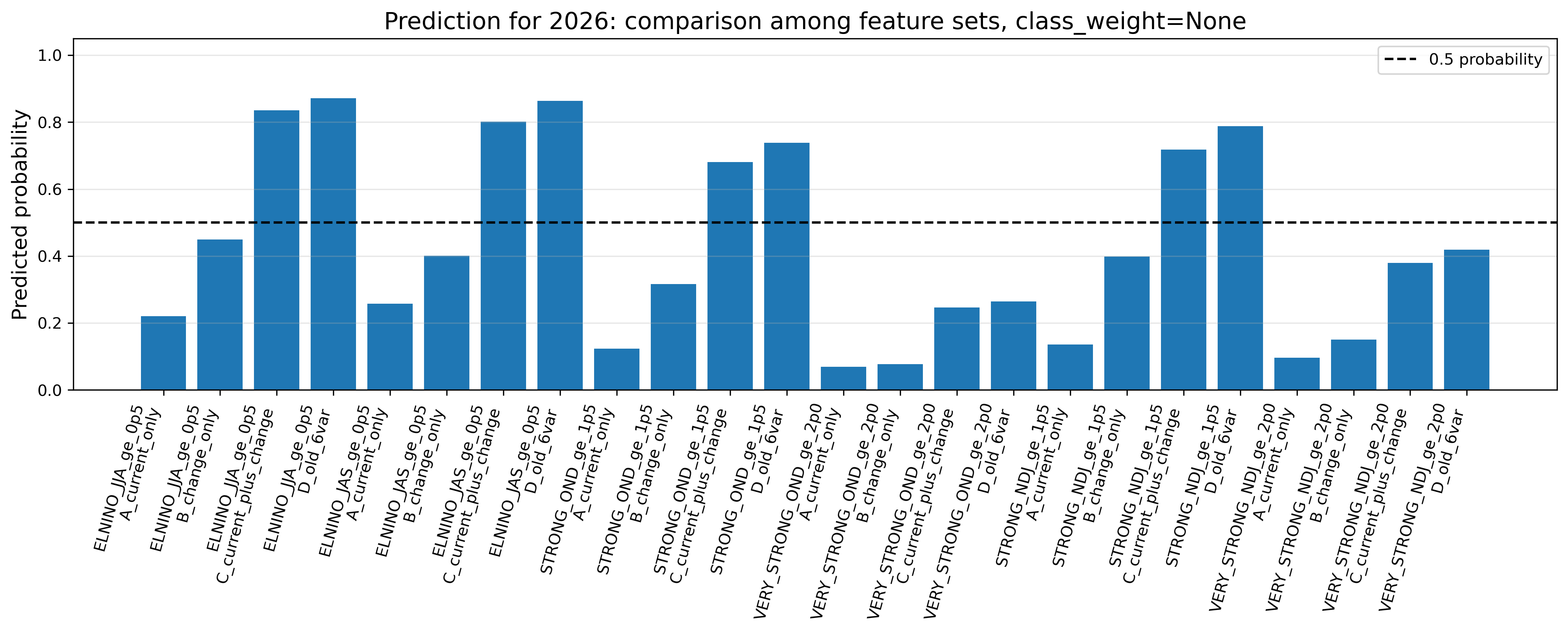
主結果として、4変数モデルかつ class_weight=None の結果を見る。これは、希少イベントに過剰な重みをかけない標準的な設定である。
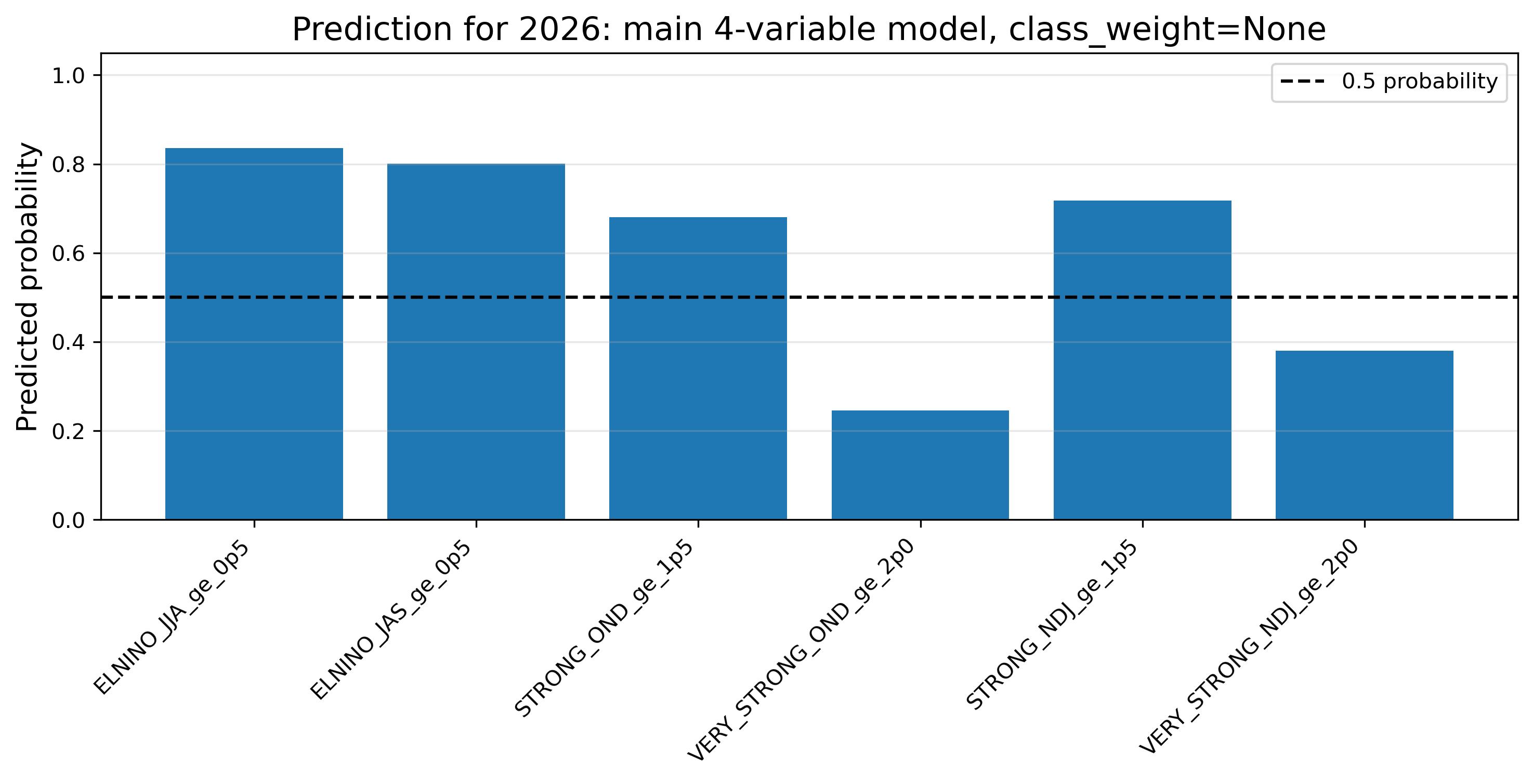
| 予測対象 | 種類 | 2026年予測確率の読み方 | 解釈 |
|---|---|---|---|
| JJA ≥ +0.5 | 発生予測 | 高い | 2026年夏にエルニーニョ条件へ入る可能性は高い。 |
| JAS ≥ +0.5 | 発生予測 | 高い | 夏〜初秋もエルニーニョ条件が続く可能性が高い。 |
| OND ≥ +1.5 | 強度予測 | やや高い | 年末に強いエルニーニョへ発達する可能性はある。 |
| OND ≥ +2.0 | very strong | 低め | 年末にvery strong級まで発達するとは、このモデルだけでは言いにくい。 |
| NDJ ≥ +1.5 | 強度予測 | やや高い | 冬に強いエルニーニョになる可能性はある。 |
| NDJ ≥ +2.0 | very strong | 中程度 | 冬にvery strong級となる可能性はあるが、不確実性が大きい。 |
主な解釈:2026年夏〜初秋にエルニーニョ条件へ入る可能性は高い。一方で、+2.0℃以上のvery strong級については、確率値だけでは判断できない。
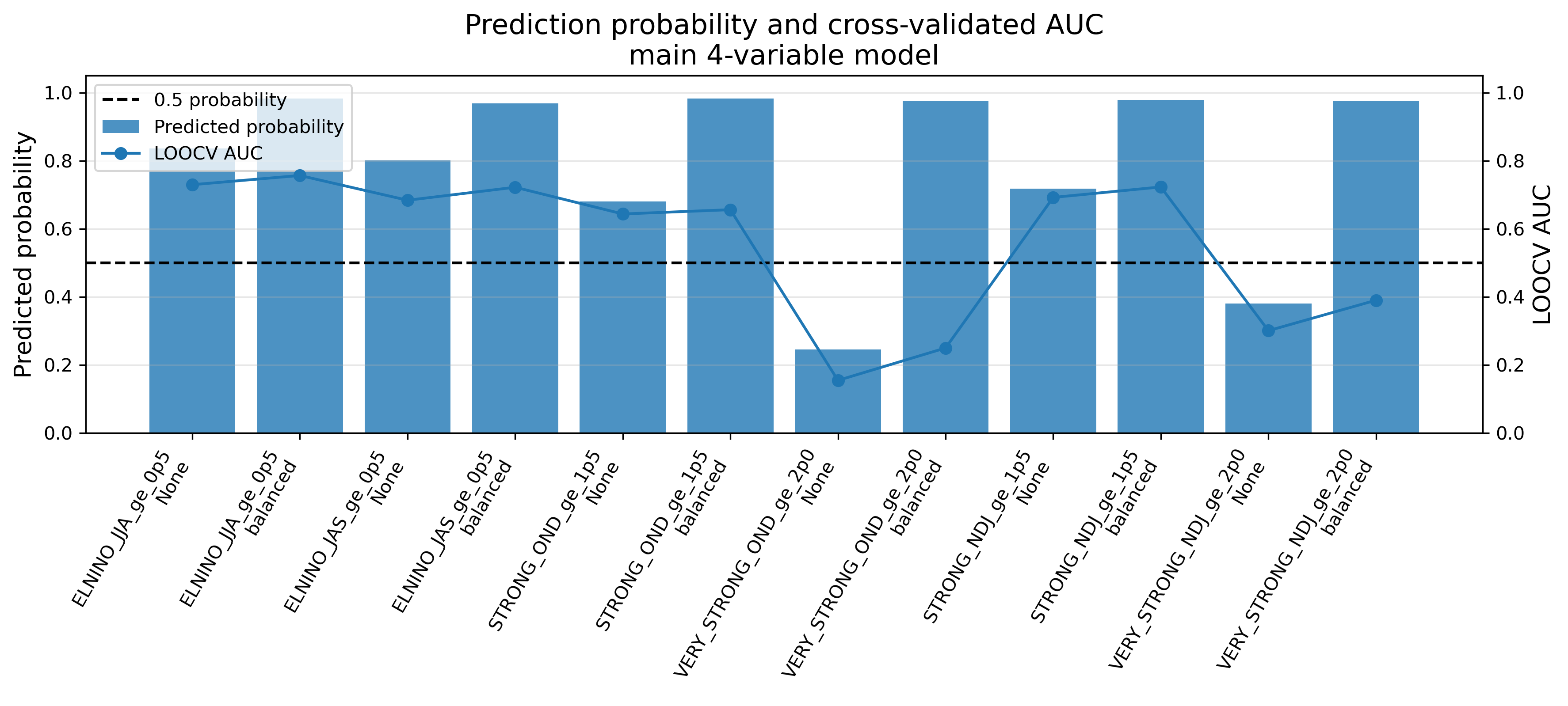
11. モデル性能:AUCとBrier score
予測確率が高くても、そのモデルが信用できるとは限らない。そこで、交差検証による性能を確認する。
| 指標 | 意味 | 読み方 |
|---|---|---|
| AUC | イベント年と非イベント年をどれだけ分けられるか | 1に近いほどよい。0.5はランダム程度。 |
| Brier score | 予測確率と実際の0/1結果のずれ | 小さいほどよい。 |
| 混同行列 | 当たり・外れの内訳 | 偽陽性や見逃しを見る。 |
12. 類似年から考える
ロジスティック回帰だけでなく、2026年4月までの状態に似ていた過去年を探すと、結果を直感的に理解しやすい。ここでは、主4変数モデルの特徴量を標準化し、2026年との距離を計算した。


| 順位 | 年 | JJA | NDJ | 結果 |
|---|---|---|---|---|
| 1 | 2023 | 1.08 | 1.89 | 強いエルニーニョ |
| 2 | 1997 | 1.25 | 2.08 | very strongまで発達 |
| 3 | 2017 | 0.20 | -0.85 | 発達せず |
| 4 | 1994 | 0.17 | 0.94 | 発達せず |
| 5 | 2002 | 0.61 | 1.13 | 夏はエルニーニョ、冬は中程度以下 |
| 6 | 1982 | 0.59 | 2.01 | very strongまで発達 |
上位の類似年には、1997年、1982年、2023年のような強いエルニーニョ年が含まれる。一方で、2017年や2013年のように発達しなかった年も含まれる。
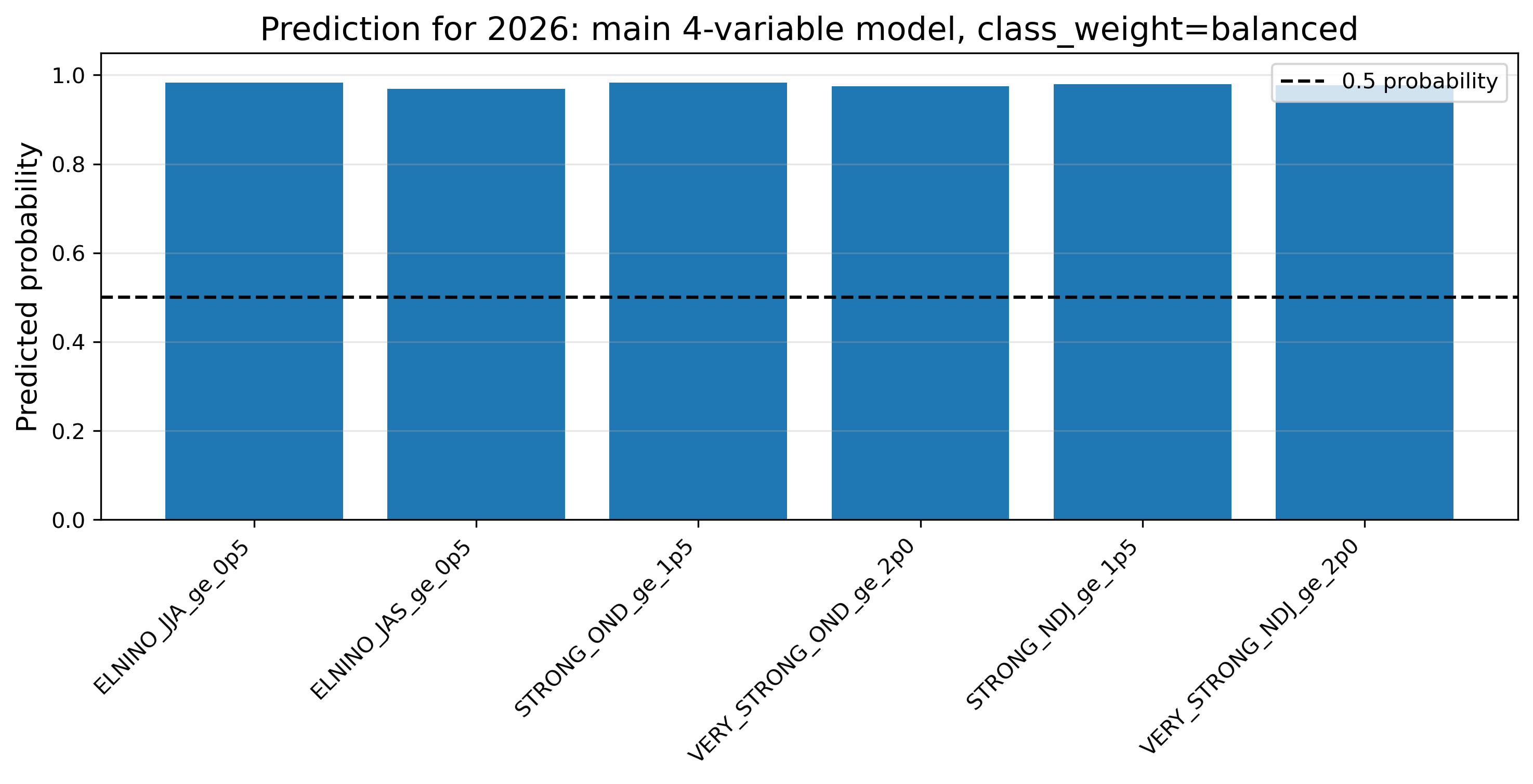
13. class_weightとは何か
今回のデータでは、強いエルニーニョやvery strong eventは珍しい。例えば、NDJ ≥ +2.0 は44年中数回しかない。このような珍しいイベントを機械学習では不均衡データという。
class_weight="balanced" を使うと、珍しいイベントを見逃さないように、イベント年を重く扱う。その結果、イベントを拾いやすくなる一方で、確率が極端に高く出ることがある。
14. スクリプトの流れと完全コード
今回の解析は、次の流れで行う。
- NINO3.4とSOIを読み込む。
- 年・月で結合する。
- 各年について、4月までに分かる特徴量を作る。
- JJA/JAS/OND/NDJのNINO3.4から目的変数を作る。
- 説明変数どうしの相関とVIFを確認する。
- ロジスティック回帰で、2026年の確率を予測する。
- 交差検証でモデル性能を確認する。
- 類似年を探して、結果を直感的に確認する。
重要:以下のコードは、このページの解析を最初から最後まで実行する完全版である。sstoi.indices と SOI_timeseries_updated2.txt を同じフォルダに置いてから、JupyterLabで実行する。
# ============================================================
# Step 1:
# ENSO prediction using NINO3.4 + SOI
#
# 目的:
# 2026年4月までの NINO3.4 と SOI から、
# 2026年夏〜冬にエルニーニョになるかを
# ロジスティック回帰で予測する。
#
# 入力ファイル:
# sstoi.indices
# SOI_timeseries_updated2.txt
#
# ============================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import LeaveOneOut, cross_val_predict
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
brier_score_loss,
roc_auc_score,
)
from sklearn.metrics import pairwise_distances
# ============================================================
# 0. 設定
# ============================================================
SST_FILE = "sstoi.indices"
SOI_FILE = "SOI_timeseries_updated2.txt"
PREDICT_YEAR = 2026
# 学習に使う年
# 1982年以降にすると、近年のENSOと比較しやすい
TRAIN_START_YEAR = 1982
TRAIN_END_YEAR = 2025
# 2026年4月までの情報で予測する
LAST_OBS_MONTH = 4
# 図を保存するかどうか
SAVE_FIG = False
# ============================================================
# 1. データ読み込み
# ============================================================
sst = pd.read_csv(SST_FILE, sep=r"\s+", engine="python")
soi = pd.read_csv(SOI_FILE, sep=r"\s+", engine="python")
print("===== Raw SST columns =====")
print(sst.columns)
print()
print("===== Raw SOI columns =====")
print(soi.columns)
print()
# ------------------------------------------------------------
# sstoi.indices の列名を整理
#
# 元の列はおそらく:
# YR MON NINO1+2 ANOM NINO3 ANOM NINO4 ANOM NINO3.4 ANOM
#
# pandasで読むと、同名ANOMは
# ANOM, ANOM.1, ANOM.2, ANOM.3
# になる。
# ------------------------------------------------------------
sst = sst.rename(
columns={
"YR": "YEAR",
"MON": "MONTH",
"ANOM": "NINO12_ANOM",
"ANOM.1": "NINO3_ANOM",
"ANOM.2": "NINO4_ANOM",
"ANOM.3": "NINO34_ANOM",
}
)
# 必要な列だけ残す
sst = sst[
[
"YEAR",
"MONTH",
"NINO1+2",
"NINO12_ANOM",
"NINO3",
"NINO3_ANOM",
"NINO4",
"NINO4_ANOM",
"NINO3.4",
"NINO34_ANOM",
]
].copy()
soi = soi[["YEAR", "MONTH", "SOI"]].copy()
# ------------------------------------------------------------
# NINO3.4 と SOI を年月で結合
# ------------------------------------------------------------
df = pd.merge(
sst[["YEAR", "MONTH", "NINO34_ANOM", "NINO3_ANOM", "NINO4_ANOM"]],
soi[["YEAR", "MONTH", "SOI"]],
on=["YEAR", "MONTH"],
how="inner",
)
df = df.sort_values(["YEAR", "MONTH"]).reset_index(drop=True)
print("===== Merged monthly data =====")
print(df.head())
print(df.tail(15))
print()
# ============================================================
# 2. 補助関数
# ============================================================
def get_month_value(data, year, month, col):
"""
指定した年・月・列の値を返す。
なければ np.nan を返す。
"""
v = data[(data["YEAR"] == year) & (data["MONTH"] == month)][col]
if len(v) == 0:
return np.nan
return float(v.iloc[0])
def get_month_mean(data, year, months, col):
"""
指定した年の複数月平均を返す。
指定月がすべて存在しない場合は np.nan。
"""
v = data[(data["YEAR"] == year) & (data["MONTH"].isin(months))][col]
if len(v) != len(months):
return np.nan
return float(v.mean())
def get_cross_year_mean(data, year, year_month_pairs, col):
"""
年をまたぐ季節平均用。
例:
NDJ_1982 = 1982年11月, 1982年12月, 1983年1月
year_month_pairs = [(1982, 11), (1982, 12), (1983, 1)]
"""
vals = []
for yy, mm in year_month_pairs:
val = get_month_value(data, yy, mm, col)
vals.append(val)
vals = np.array(vals, dtype=float)
if np.any(np.isnan(vals)):
return np.nan
return float(np.mean(vals))
def season_mean(data, year, season_name, col):
"""
季節平均を返す。
JJA: 6,7,8月
JAS: 7,8,9月
OND: 10,11,12月
NDJ: 11,12月 + 翌年1月
"""
if season_name == "JJA":
return get_month_mean(data, year, [6, 7, 8], col)
elif season_name == "JAS":
return get_month_mean(data, year, [7, 8, 9], col)
elif season_name == "OND":
return get_month_mean(data, year, [10, 11, 12], col)
elif season_name == "NDJ":
return get_cross_year_mean(
data,
year,
[(year, 11), (year, 12), (year + 1, 1)],
col,
)
else:
raise ValueError("Unknown season name.")
# ============================================================
# 3. 年ごとの特徴量テーブルを作る
# ============================================================
#
# ここでは「4月までにわかっている情報」だけを特徴量にする。
# 未来の情報を特徴量に入れないことが重要。
#
# ============================================================
rows = []
for year in range(TRAIN_START_YEAR, TRAIN_END_YEAR + 1):
n34_jan = get_month_value(df, year, 1, "NINO34_ANOM")
n34_feb = get_month_value(df, year, 2, "NINO34_ANOM")
n34_mar = get_month_value(df, year, 3, "NINO34_ANOM")
n34_apr = get_month_value(df, year, 4, "NINO34_ANOM")
soi_jan = get_month_value(df, year, 1, "SOI")
soi_feb = get_month_value(df, year, 2, "SOI")
soi_mar = get_month_value(df, year, 3, "SOI")
soi_apr = get_month_value(df, year, 4, "SOI")
row = {
"YEAR": year,
# ----------------------------
# NINO3.4 features
# ----------------------------
"NINO34_Jan": n34_jan,
"NINO34_Feb": n34_feb,
"NINO34_Mar": n34_mar,
"NINO34_Apr": n34_apr,
"NINO34_FMA": get_month_mean(df, year, [2, 3, 4], "NINO34_ANOM"),
"NINO34_JanApr_mean": get_month_mean(df, year, [1, 2, 3, 4], "NINO34_ANOM"),
"NINO34_JanApr_change": n34_apr - n34_jan,
"NINO34_FebApr_change": n34_apr - n34_feb,
"NINO34_MarApr_change": n34_apr - n34_mar,
# ----------------------------
# SOI features
# ----------------------------
"SOI_Jan": soi_jan,
"SOI_Feb": soi_feb,
"SOI_Mar": soi_mar,
"SOI_Apr": soi_apr,
"SOI_FMA": get_month_mean(df, year, [2, 3, 4], "SOI"),
"SOI_JanApr_mean": get_month_mean(df, year, [1, 2, 3, 4], "SOI"),
"SOI_JanApr_change": soi_apr - soi_jan,
"SOI_FebApr_change": soi_apr - soi_feb,
"SOI_MarApr_change": soi_apr - soi_mar,
# ----------------------------
# 予測対象になる将来のNINO3.4
# ここは教師データなので、2026年の予測には使わない
# ----------------------------
"NINO34_JJA": season_mean(df, year, "JJA", "NINO34_ANOM"),
"NINO34_JAS": season_mean(df, year, "JAS", "NINO34_ANOM"),
"NINO34_OND": season_mean(df, year, "OND", "NINO34_ANOM"),
"NINO34_NDJ": season_mean(df, year, "NDJ", "NINO34_ANOM"),
}
rows.append(row)
yearly = pd.DataFrame(rows)
# 欠損を落とす前の確認
print("===== Yearly table before dropna =====")
print(yearly.tail())
print()
# ============================================================
# 4. 目的変数を作る
# ============================================================
#
# 発生予測:
# JJA >= 0.5
# JAS >= 0.5
#
# 強度予測:
# OND >= 1.5
# OND >= 2.0
# NDJ >= 1.5
# NDJ >= 2.0
#
# ============================================================
target_definitions = {
"ELNINO_JJA_ge_0p5": {
"target_column": "NINO34_JJA",
"threshold": 0.5,
"description": "JJA NINO3.4 >= 0.5 degC",
},
"ELNINO_JAS_ge_0p5": {
"target_column": "NINO34_JAS",
"threshold": 0.5,
"description": "JAS NINO3.4 >= 0.5 degC",
},
"STRONG_OND_ge_1p5": {
"target_column": "NINO34_OND",
"threshold": 1.5,
"description": "OND NINO3.4 >= 1.5 degC",
},
"VERY_STRONG_OND_ge_2p0": {
"target_column": "NINO34_OND",
"threshold": 2.0,
"description": "OND NINO3.4 >= 2.0 degC",
},
"STRONG_NDJ_ge_1p5": {
"target_column": "NINO34_NDJ",
"threshold": 1.5,
"description": "NDJ NINO3.4 >= 1.5 degC",
},
"VERY_STRONG_NDJ_ge_2p0": {
"target_column": "NINO34_NDJ",
"threshold": 2.0,
"description": "NDJ NINO3.4 >= 2.0 degC",
},
}
for event_name, info in target_definitions.items():
target_col = info["target_column"]
threshold = info["threshold"]
yearly[event_name] = yearly[target_col] >= threshold
# ============================================================
# 5. 2026年4月時点の特徴量を作る
# ============================================================
year = PREDICT_YEAR
n34_jan = get_month_value(df, year, 1, "NINO34_ANOM")
n34_feb = get_month_value(df, year, 2, "NINO34_ANOM")
n34_mar = get_month_value(df, year, 3, "NINO34_ANOM")
n34_apr = get_month_value(df, year, 4, "NINO34_ANOM")
soi_jan = get_month_value(df, year, 1, "SOI")
soi_feb = get_month_value(df, year, 2, "SOI")
soi_mar = get_month_value(df, year, 3, "SOI")
soi_apr = get_month_value(df, year, 4, "SOI")
x_predict = pd.DataFrame(
[
{
"NINO34_Jan": n34_jan,
"NINO34_Feb": n34_feb,
"NINO34_Mar": n34_mar,
"NINO34_Apr": n34_apr,
"NINO34_FMA": get_month_mean(df, year, [2, 3, 4], "NINO34_ANOM"),
"NINO34_JanApr_mean": get_month_mean(df, year, [1, 2, 3, 4], "NINO34_ANOM"),
"NINO34_JanApr_change": n34_apr - n34_jan,
"NINO34_FebApr_change": n34_apr - n34_feb,
"NINO34_MarApr_change": n34_apr - n34_mar,
"SOI_Jan": soi_jan,
"SOI_Feb": soi_feb,
"SOI_Mar": soi_mar,
"SOI_Apr": soi_apr,
"SOI_FMA": get_month_mean(df, year, [2, 3, 4], "SOI"),
"SOI_JanApr_mean": get_month_mean(df, year, [1, 2, 3, 4], "SOI"),
"SOI_JanApr_change": soi_apr - soi_jan,
"SOI_FebApr_change": soi_apr - soi_feb,
"SOI_MarApr_change": soi_apr - soi_mar,
}
]
)
print(f"===== Features for {PREDICT_YEAR} April =====")
print(x_predict.T)
print()
# ============================================================
# 6. 使用する特徴量
# ============================================================
#
# 特徴量を増やしすぎると、44年程度のデータでは過学習しやすい。
# ここでは説明しやすい6個に絞る。
#
# ============================================================
features = [
"NINO34_Apr",
"NINO34_FMA",
"NINO34_JanApr_change",
"SOI_Apr",
"SOI_FMA",
"SOI_JanApr_change",
]
# ============================================================
# 7. ロジスティック回帰を実行する関数
# ============================================================
def run_logistic_model(yearly_data, event_name, class_weight_option):
"""
指定したイベントについてロジスティック回帰を実行する。
class_weight_option は None または "balanced"。
"""
info = target_definitions[event_name]
target_col = info["target_column"]
# 使う列だけ取り出して欠損を落とす
cols_needed = ["YEAR"] + features + [target_col, event_name]
data = yearly_data[cols_needed].dropna().reset_index(drop=True)
X = data[features]
y = data[event_name].astype(int)
n_total = len(y)
n_event = int(y.sum())
event_rate = y.mean()
print("=" * 70)
print("Target:", event_name)
print("Description:", info["description"])
print("class_weight:", class_weight_option)
print("Training years:", int(data["YEAR"].min()), "-", int(data["YEAR"].max()))
print("Number of years:", n_total)
print("Number of event years:", n_event)
print("Historical frequency:", event_rate)
if y.nunique() < 2:
print("This target has only one class. Logistic regression is skipped.")
print("=" * 70)
print()
return None
model = make_pipeline(
StandardScaler(),
LogisticRegression(
class_weight=class_weight_option,
max_iter=1000,
random_state=0,
),
)
# 学習
model.fit(X, y)
# 2026年予測
prob_2026 = model.predict_proba(x_predict[features])[0, 1]
print(f"Predicted probability for {PREDICT_YEAR}: {prob_2026:.3f}")
# --------------------------------------------------------
# Leave-One-Out Cross Validation
# --------------------------------------------------------
loo = LeaveOneOut()
prob_cv = cross_val_predict(
model,
X,
y,
cv=loo,
method="predict_proba",
)[:, 1]
pred_cv = prob_cv >= 0.5
acc = accuracy_score(y, pred_cv)
brier = brier_score_loss(y, prob_cv)
print("LOOCV Accuracy:", f"{acc:.3f}")
print("LOOCV Brier score:", f"{brier:.3f}")
try:
auc = roc_auc_score(y, prob_cv)
print("LOOCV ROC AUC:", f"{auc:.3f}")
except ValueError:
auc = np.nan
print("LOOCV ROC AUC: cannot be calculated")
cm = confusion_matrix(y, pred_cv)
print("Confusion matrix:")
print(cm)
# --------------------------------------------------------
# 係数
# --------------------------------------------------------
logreg = model.named_steps["logisticregression"]
coef = logreg.coef_[0]
coef_table = pd.DataFrame(
{
"feature": features,
"coef_standardized": coef,
}
).sort_values("coef_standardized", ascending=False)
print("Standardized coefficients:")
print(coef_table)
print("=" * 70)
print()
# --------------------------------------------------------
# 結果をまとめる
# --------------------------------------------------------
result = {
"event_name": event_name,
"description": info["description"],
"class_weight": class_weight_option,
"n_total": n_total,
"n_event": n_event,
"historical_frequency": event_rate,
"prob_2026": prob_2026,
"accuracy": acc,
"brier": brier,
"auc": auc,
"confusion_matrix": cm,
"coef_table": coef_table,
"data": data,
"prob_cv": prob_cv,
"pred_cv": pred_cv,
"model": model,
}
return result
# ============================================================
# 8. 全ターゲットについて実行
# ============================================================
results = []
for event_name in target_definitions.keys():
# class_weightなし
res_none = run_logistic_model(
yearly_data=yearly,
event_name=event_name,
class_weight_option=None,
)
if res_none is not None:
results.append(res_none)
# class_weightあり
res_balanced = run_logistic_model(
yearly_data=yearly,
event_name=event_name,
class_weight_option="balanced",
)
if res_balanced is not None:
results.append(res_balanced)
# ============================================================
# 9. 結果一覧表
# ============================================================
summary_rows = []
for res in results:
summary_rows.append(
{
"event": res["event_name"],
"description": res["description"],
"class_weight": str(res["class_weight"]),
"n_total": res["n_total"],
"n_event": res["n_event"],
"historical_frequency": res["historical_frequency"],
"prob_2026": res["prob_2026"],
"LOOCV_accuracy": res["accuracy"],
"LOOCV_brier": res["brier"],
"LOOCV_auc": res["auc"],
}
)
summary = pd.DataFrame(summary_rows)
print("===== Summary of logistic regression predictions =====")
print(summary)
print()
summary.to_csv("step1_logistic_summary.csv", index=False)
print("Saved: step1_logistic_summary.csv")
# ============================================================
# 10. 2026年に似た過去年を探す
# ============================================================
# 類似年探索では、全ターゲット共通で特徴量だけを見る
analog_data = yearly[["YEAR"] + features + ["NINO34_JJA", "NINO34_JAS", "NINO34_OND", "NINO34_NDJ"]].dropna().reset_index(drop=True)
X_analog = analog_data[features]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_analog)
x_scaled = scaler.transform(x_predict[features])
dist = pairwise_distances(X_scaled, x_scaled).ravel()
analog_data["distance_from_2026"] = dist
analog_sorted = analog_data.sort_values("distance_from_2026").reset_index(drop=True)
print("===== Top 15 analog years based on Jan-Apr NINO3.4 and SOI =====")
print(
analog_sorted[
[
"YEAR",
"distance_from_2026",
"NINO34_JJA",
"NINO34_JAS",
"NINO34_OND",
"NINO34_NDJ",
"NINO34_Apr",
"NINO34_JanApr_change",
"SOI_Apr",
"SOI_JanApr_change",
]
].head(15)
)
print()
analog_sorted.to_csv("step1_analog_years.csv", index=False)
print("Saved: step1_analog_years.csv")
# ============================================================
# 11. 図1:2026年の予測確率一覧
# ============================================================
plt.figure(figsize=(12, 5))
plot_df = summary.copy()
plot_df["label"] = plot_df["event"] + "\n" + plot_df["class_weight"]
x = np.arange(len(plot_df))
plt.bar(x, plot_df["prob_2026"])
plt.axhline(0.5, linestyle="--", color="k", label="0.5")
plt.xticks(x, plot_df["label"], rotation=60, ha="right")
plt.ylabel("Predicted probability")
plt.title(f"Logistic-regression prediction for {PREDICT_YEAR}")
plt.grid(True, axis="y", alpha=0.3)
plt.legend()
plt.tight_layout()
if SAVE_FIG:
plt.savefig("step1_probability_summary.png", dpi=300)
plt.show()
# ============================================================
# 12. 図2:NINO3.4 時系列とターゲット
# ============================================================
plt.figure(figsize=(11, 4))
plt.plot(
yearly["YEAR"],
yearly["NINO34_JJA"],
marker="o",
label="JJA",
)
plt.plot(
yearly["YEAR"],
yearly["NINO34_OND"],
marker="s",
label="OND",
)
plt.plot(
yearly["YEAR"],
yearly["NINO34_NDJ"],
marker="^",
label="NDJ",
)
plt.axhline(0.5, linestyle="--", color="k", label="+0.5")
plt.axhline(1.5, linestyle=":", color="k", label="+1.5")
plt.axhline(2.0, linestyle="-.", color="k", label="+2.0")
plt.xlabel("Year")
plt.ylabel("NINO3.4 anomaly")
plt.title("Observed seasonal NINO3.4 anomalies")
plt.grid(True, alpha=0.3)
plt.legend(ncol=3)
plt.tight_layout()
if SAVE_FIG:
plt.savefig("step1_observed_seasonal_nino34.png", dpi=300)
plt.show()
# ============================================================
# 13. 図3:4月NINO3.4と夏・冬NINO3.4の関係
# ============================================================
plt.figure(figsize=(6, 5))
plt.scatter(
yearly["NINO34_Apr"],
yearly["NINO34_JJA"],
label="JJA",
alpha=0.8,
)
plt.scatter(
yearly["NINO34_Apr"],
yearly["NINO34_NDJ"],
label="NDJ",
alpha=0.8,
)
plt.axhline(0.5, linestyle="--", color="k", label="+0.5")
plt.axhline(1.5, linestyle=":", color="k", label="+1.5")
plt.axhline(2.0, linestyle="-.", color="k", label="+2.0")
plt.axvline(
x_predict["NINO34_Apr"].iloc[0],
linestyle="--",
color="k",
label=f"{PREDICT_YEAR} Apr",
)
plt.xlabel("NINO3.4 anomaly in April")
plt.ylabel("Future seasonal NINO3.4 anomaly")
plt.title("April NINO3.4 vs future ENSO strength")
plt.grid(True, alpha=0.3)
plt.legend()
plt.tight_layout()
if SAVE_FIG:
plt.savefig("step1_april_vs_future_nino34.png", dpi=300)
plt.show()
# ============================================================
# 14. 図4:類似年の結果
# ============================================================
top = analog_sorted.head(15).copy()
plt.figure(figsize=(11, 4))
x = np.arange(len(top))
plt.bar(x - 0.2, top["NINO34_JJA"], width=0.4, label="JJA")
plt.bar(x + 0.2, top["NINO34_NDJ"], width=0.4, label="NDJ")
plt.axhline(0.5, linestyle="--", color="k", label="+0.5")
plt.axhline(1.5, linestyle=":", color="k", label="+1.5")
plt.axhline(2.0, linestyle="-.", color="k", label="+2.0")
plt.xticks(x, top["YEAR"].astype(str), rotation=45)
plt.xlabel("Analog year")
plt.ylabel("NINO3.4 anomaly")
plt.title(f"Future ENSO outcomes of analog years similar to {PREDICT_YEAR} Jan-Apr state")
plt.grid(True, axis="y", alpha=0.3)
plt.legend(ncol=4)
plt.tight_layout()
if SAVE_FIG:
plt.savefig("step1_analog_year_outcomes.png", dpi=300)
plt.show()
# ============================================================
# 15. 重要な確認メッセージ
# ============================================================
print("===== Interpretation notes =====")
print("1. JJA/JAS >= 0.5 is an onset-type prediction.")
print("2. OND/NDJ >= 1.5 or >= 2.0 is a strength-type prediction.")
print("3. class_weight='balanced' often gives higher probabilities for rare events.")
print("4. Very strong events are rare, so probabilities are uncertain.")
print("5. This model uses only NINO3.4 and SOI. It does not use subsurface heat content, winds, or dynamical models.")
- なぜ、5月以降の値を説明変数に入れてはいけないのか。
- JJA ≥ +0.5 と NDJ ≥ +2.0 は、同じ「エルニーニョ予測」と言ってよいか。
- 予測確率が高いのにAUCが低い場合、どう解釈すべきか。
- class_weight="balanced" は、どのような利点と欠点を持つか。
- なぜ、旧6変数モデルではVIFが大きくなったのか。
- VIFが大きいと、予測結果と係数解釈にどのような問題が起こるか。
15. 結果の見方
15.1 発生予測
JJA ≥ +0.5 と JAS ≥ +0.5 の予測確率は、主4変数モデルでも高い。したがって、2026年夏〜初秋にエルニーニョ条件へ入る可能性は高いと読むことができる。
15.2 強度予測
OND ≥ +1.5 と NDJ ≥ +1.5 も比較的高い確率になっている。ただし、過去の発生数は少なく、強いイベントの予測は不確実性が大きい。
15.3 very strong / スーパー級
OND ≥ +2.0 や NDJ ≥ +2.0 は、過去の事例数がさらに少ない。特にAUCが低いため、このモデルはvery strong eventを安定して見分けられていない。したがって、スーパーエルニーニョ級になる可能性はあるが、このモデルだけでは判断できないと結論する。
15.4 VIFを使ったモデル選択
旧6変数モデルではVIFが非常に大きく、特にNINO34_FMAのVIFは50を超えた。このため、似た情報を重複して使っていたと判断できる。主4変数モデルではVIFがすべて3未満であり、説明しやすく、係数解釈も旧モデルより安定している。
16. まとめ
- 2026年4月時点で、NINO3.4は +0.47℃まで上昇し、+0.5℃の目安に近づいている。
- SOIは4月に負へ反転し、大気側もエルニーニョ方向へ変化している。
- 主モデルは、NINO3.4とSOIの4月値、および1月から4月までの変化量を使う4変数モデルとした。
- 旧6変数モデルではVIFが30〜50を超える変数があり、多重共線性が強かった。
- 主4変数モデルではVIFがすべて3未満であり、多重共線性は深刻ではない。
- ロジスティック回帰では、2026年夏〜初秋にエルニーニョ条件へ入る確率は高く推定された。
- ただし、+2.0℃以上のvery strong eventは事例数が少なく、モデル性能も低いため慎重に解釈する必要がある。
- 予測確率だけでなく、AUC、Brier score、類似年の結果、多重共線性、VIFを合わせて読むことが重要である。